Regular expressions are notations for describing patterns of text and, in effect, make up a special-purpose language for pattern matching. Although there are myriad variants, all share the idea that most characters in a pattern match literal occurrences of themselves, but some metacharacters have special meaning, such as * to indicate some kind of repetition or […] to mean any one character from the set within the brackets.
Beautiful Code by Andy Oram, Greg Wilson
More simply, Regex (short for regular expression), is a string of text that allows you to create patterns that help match, locate, and manage text.
Below is a quick reference Javascript regex cheat sheet. If you need a more in depth refresher or a place to get started I recommend these resources on regex:
Disclaimer: For educational and demonstrative purposes only. Always test your regular expressions before applying anything to a production system. Results from the above tool are not guaranteed.
How To Use:
Type a regular expression in the Regex input box. (Leading and ending slashes are added automatically)
Type a sample string to match against in the other box.
Check out the resulting matches.
Tweak your regex expression until you get the expected results to test your knowledge.
The advent of “Big Data” is relatively new and is loosely defined as data that contains greater variety, arriving in increasing volumes and with more velocity. This is also known as the Three Vs. Greater than what? Well, greater than the data that would traditional be handled by a traditional Relational Database Management System (RDBMS).
The Three V’s
Volume – Every day, global data volume is increasing exponentially. There are many cultural, scientific and technological reasons for this including the invention and proliferation of smart phones, wearable technology, IoT devices, cloud computing, machine learning and artificial intelligence.
Velocity – The rate at which data is received and processed. Velocity has less to do with the aforementioned exponential growth of data being stored and more to do with real time streaming of that data and the need to process said data in near real time. Traditional ETL pipelines that operated on daily or even hourly batch processing just aren’t enough and so new solutions that could derive meaningful insights from data sets as they were coming in were necessary.
Variety – The increasingly varied types of data that were being processed. Constraining usable data to a predefined schema (structured data) had and still does have its advantages and in a perfect world all data would automagically be this way. But in the real world, big data solutions offer flexibility to process data much more quickly and in new ways that never would have been possible with traditional RDMS structures. These unstructured and semi-structured data types, such as text, audio, and video, require additional preprocessing to derive meaning and support metadata.
Data Structures
In the context of processing, storage and analysis, all data that exists can be categorized as either structured, unstructured or semi-structured.
Structured Data
Sometimes referred to as quantitative data. This is how all data in the enterprise used to be stored at scale. Structured data is data whose elements are addressable for effective analysis. It has been organized into a formatted repository that is typically a database. They have relational keys and can easily be mapped into pre-designed fields.
Unstructured Data
Unstructured data is a data which is not organized in a predefined manner or does not have a predefined data model, thus it is not a good fit for a mainstream relational database. It’s sometimes referred to qualitative data — you can derive meaning from it, but it can also be incredibly ambiguous and difficult to parse.
Semi-Structured Data
Data that does not reside in a relational database but that has some organizational properties that make it easier to analyze. This data probably is not as strictly typed as structured data but does enforce some rules such as hierarchy and nesting.
The job of a Building Architect is typically to design buildings, structures and civil infrastructure. Not too dissimilarly, the job of a Software Architect is to design the systems, services and infrastructure of computing systems. More importantly, just like as building architectural planning is typically the first step in any major construction project, so too is software architecture (albeit, one of the two is better suited to an agile methodology).
What is an Architectural Pattern?
An architectural pattern is a general, reusable solution to a commonly occurring problem in software architecture within a given context. The architectural patterns address various issues in software engineering, such as computer hardware performance limitations, high availability and minimization of a business risk.
You can think of an Architectural Pattern as a sort of “template” that you can use as a first step when designing the architecture of your system or application; it is not, in and of itself, an architecture. Rather, an architectural pattern is generally considered “strictly described and commonly available”. They’re designed to be broad and represent high level solutions to general software engineering problems that are reoccurring.
Just like there are many different “styles” of Building Architecture (i.e. Classical, Industrial, Victorian, Tudor, Art Deco, ect.) Software Architecture has “Patterns”.
Why use an established Architectural Pattern?
It’s good to learn from your mistakes. It’s better to learn from other people’s mistakes.
Warren Buffett, CEO of Berkshire Hathaway
Like I said before, an architectural pattern is a starting point; a template. Starting with the model that most closely fits your project’s needs has advantages:
More optimized systems – by using architectural patterns, we build transferrable models that can be reused, thus making them scalable and extensible.
Early design changes – most architectural patterns are flexible and provide you the opportunity to examine your project holistically so that you can work out errors or fundamental changes that need to be made before technical debt is accrued.
Simplification – not just for your sake but for the sake of collaboration among all the stakeholders involved. The faster stakeholders can form a mutual understanding, the faster communication, negotiation, and consensus. Obfuscation never solved anything.
Common Architectural Patterns
Below are just some of today’s most commonly used patterns:
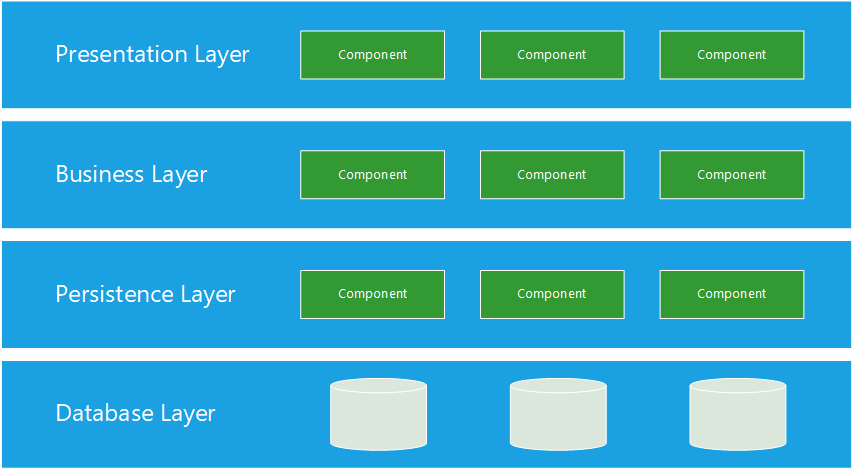
Layered
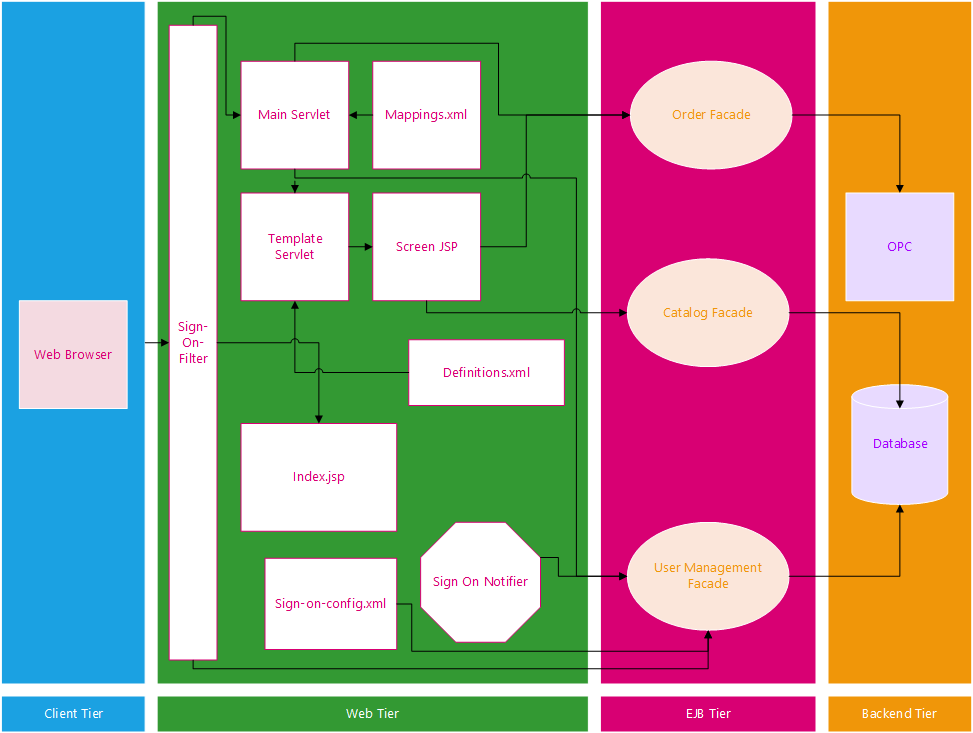
Multi-Tier
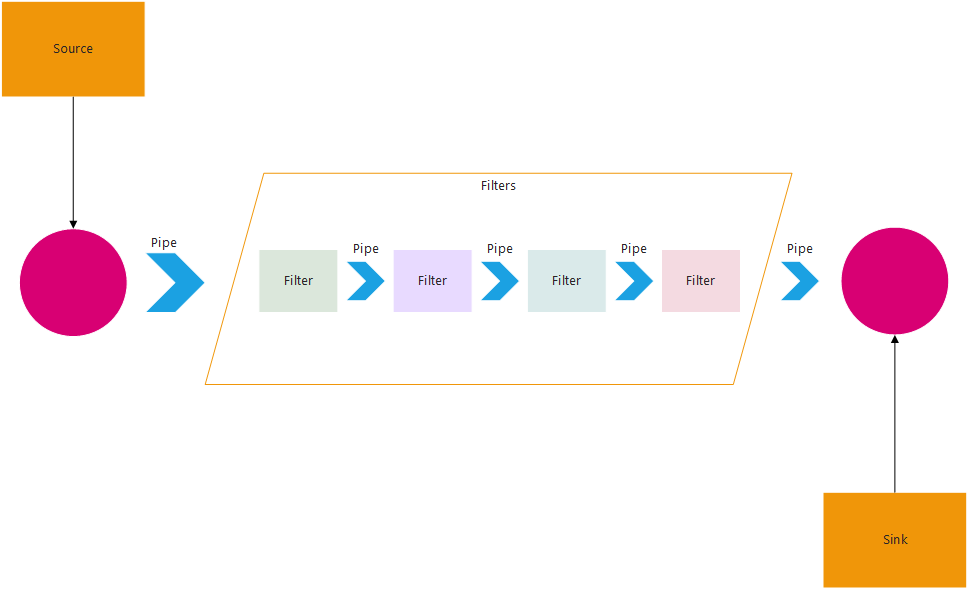
Pipe and Filter
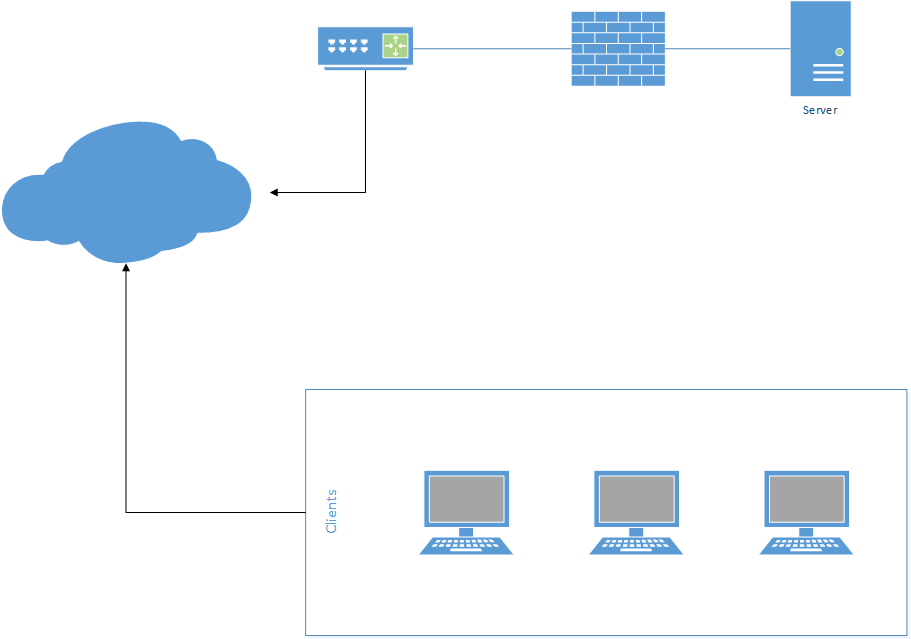
Client Server
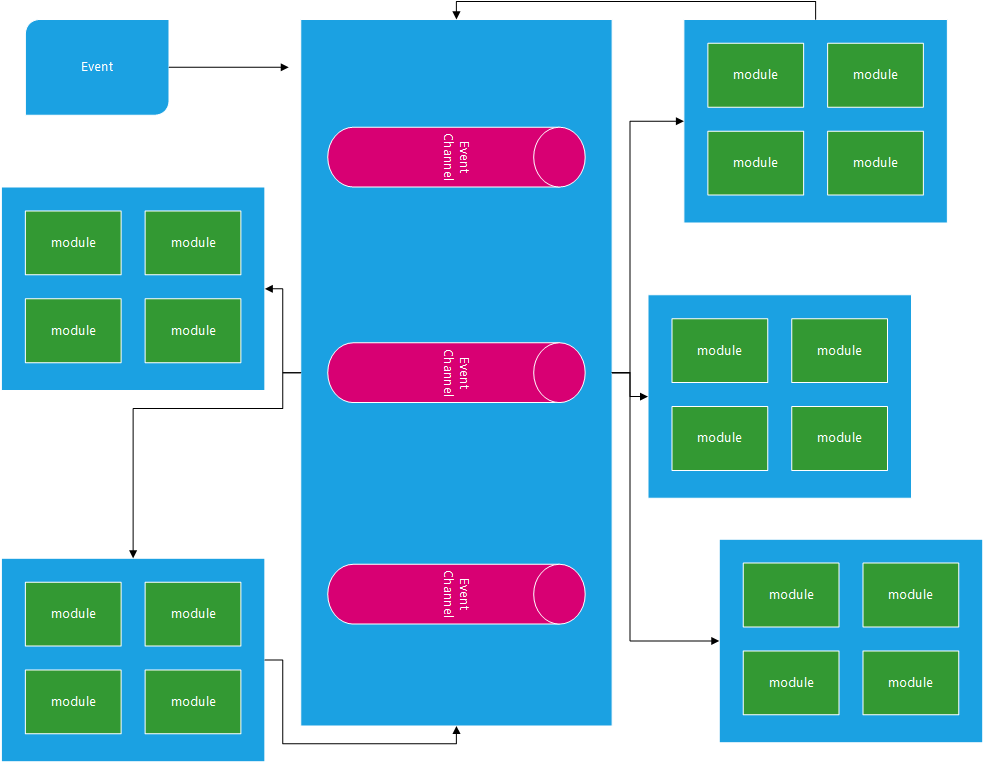
Event-Driven
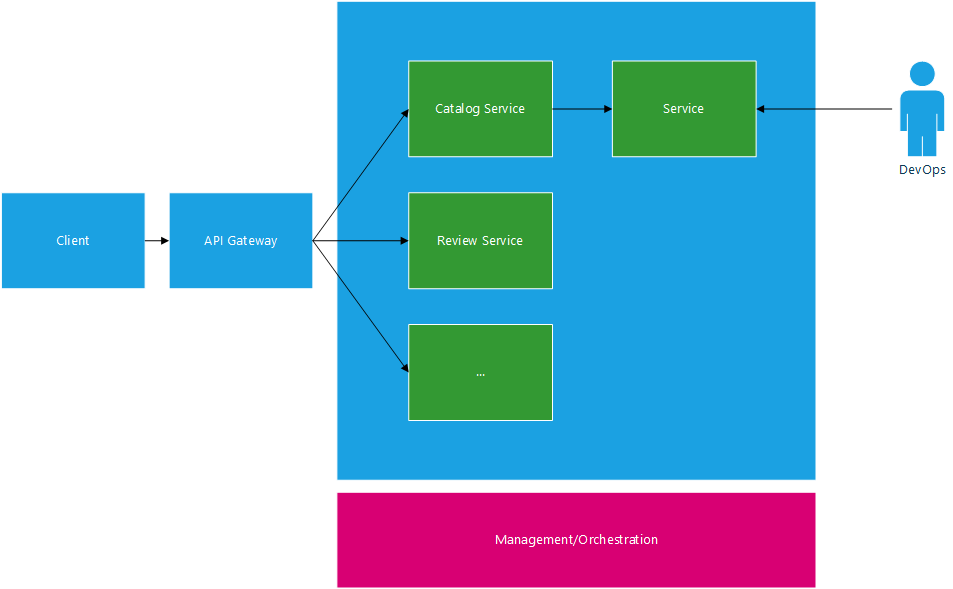
Microservices
There are many many other architectural patterns out there and this only represents a small subset of those. I may cover some of these plus others in more detail in the future via a separate post.
Below are high level conceptual diagrams for each of the above.
Suppose that you setup a new Transactional Replication topology in Microsoft SQL Server, the scripts execute successfully and/or the wizard shows no errors. Despite this, when you try to run the log reader, snapshot, distribution or other agent for the first time it starts up successfully but then stops. When you check the job history or the replication monitor you might see an error like this:
2021-06-23 18:31:45.110 Status: 0, code: 20015, text: ‘Named Pipes Provider: Could not open a connection to SQL Server [2]. A network-related or instance-specific error has occurred while establishing a connection to SQL Server. Server is not found or not accessible. Check if instance name is correct and if SQL Server is configured to allow remote connections. For more information see SQL Server Books Online.Query timeout expired, Failed Command: ‘.
2021-06-23 18:31:45.110 Named Pipes Provider: Could not open a connection to SQL Server [2]. A network-related or instance-specific error has occurred while establishing a connection to SQL Server. Server is not found or not accessible. Check if instance name is correct and if SQL Server is configured to allow remote connections. For more information see SQL Server Books Online.Query timeout expired, Failed Command:
2021-06-23 18:32:45.233 Microsoft SQL Server Log Reader Agent 13.0.5888.11
This error is normally caused by either a connection timeout or improper permissions on the agent account.
Troubleshooting
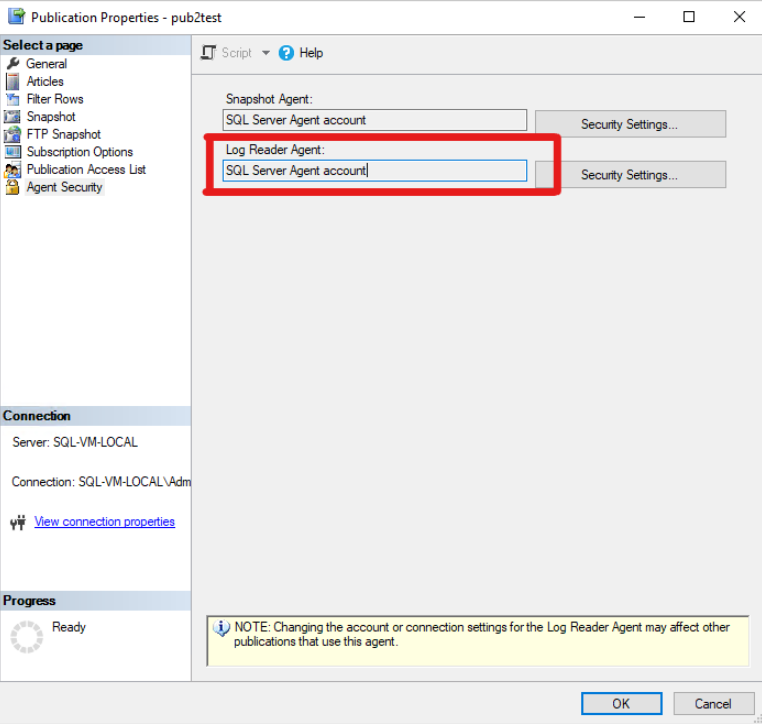
The first thing you should do is confirm that the agent is using the account you think it is using. In this case I am checking the Log Reader Agent. You can verify the account that is in use via SSMS:
For Log Reader Agent and Snapshot Agent accounts:
Object Explorer -> Replication -> Local Publications -> Right Click [your_publication] -> Properties -> Agent Security -> Log Reader Agent
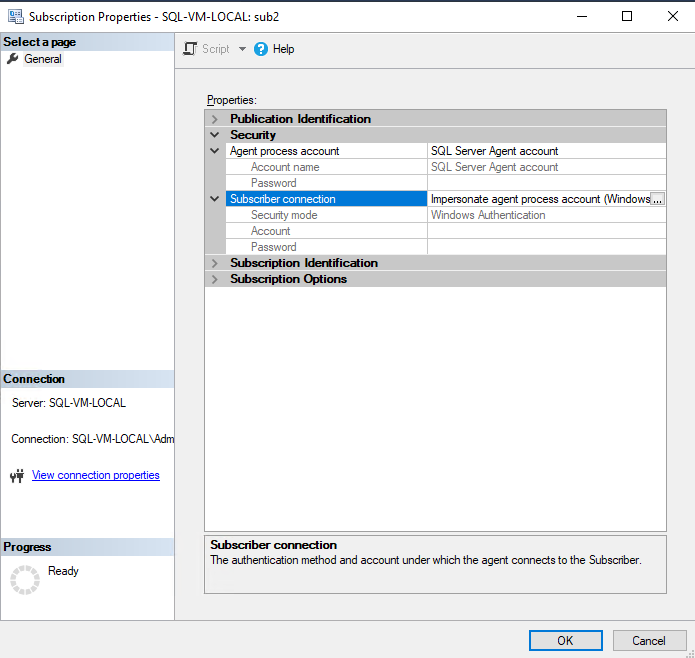
For Distribution Agent and Merge Agent accounts:
Object Explorer -> Replication -> Local Publications -> Expand [your_publication] -> Right Click [your_subscription] -> Properties -> Expand Security
Next, you should make sure that you can successfully establish a connection bidirectionally between your Publisher <-> Distributor, and Distributor<-> Subscriber.
NOTE: Remember that for replication to work properly you need to have SQL Server ports (1433 by default for the default instance) open for both incoming and outgoing connections on your Publisher, Distributor and Subscriber(s).
In special circumstances with an unreliable network or if you’re using Replication in conjunction with Always On AG, it may be necessary to increase the server connection timeout and/or the linked servers remote login timeout which you can do with the following TSQL scripts:
Connection Timeout:
/*This has to be done for each linked server. Best to use 'remote login timeout' */
EXEC master.dbo.sp_serveroption
@server=N'repl_distributor',
@optname=N'connect timeout',
@optvalue=N'60'
Remote Login Timeout:
/*This setting applies to all linked servers */
sp_configure 'remote login timeout (s)', 60
go
reconfigure
go
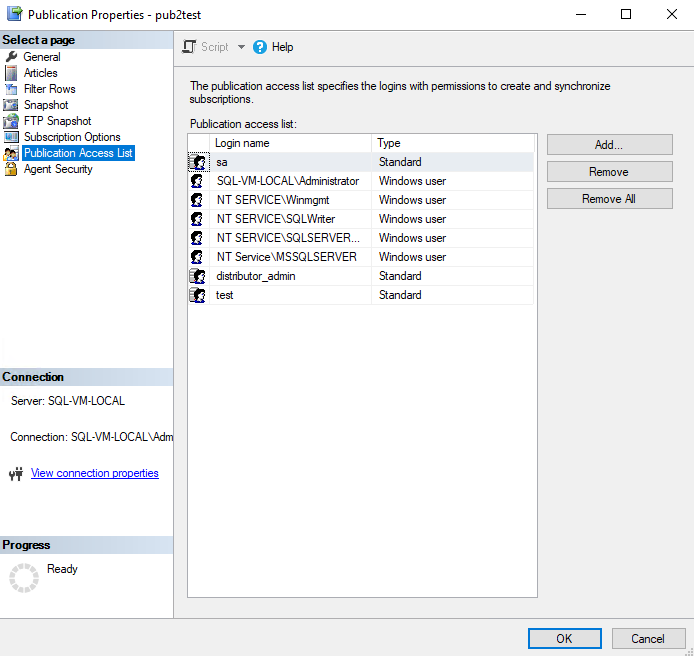
If you’re troubleshooting a distribution agent or a merge agent make sure that the agent account is added to the Publication Access List (PAL) which you can check via SSMS:
Object Explorer -> Replication -> Local Publications -> Right Click [your_publication] -> Properties -> Publication Access List
In this case we are using Transactional Replication and distributor_admin is the agent account used by our distribution agent.
Lastly, we want to check the account type and make sure that the proper permissions are mapped. Below are the steps to check the account for the Log Reader Agent. For the Distribution Agent or Merge Agent you will follow a similar procedure except user mappings will be on the Subscriber instead of the Publisher. The steps for the distribution database still apply.
If Log Reader Agent is Domain Account:
Connect to Publisher:
Check: Object Explorer -> Security -> Logins
If already DOES exists: Right click login -> properties -> User Mappings -> [your publication database] -> Make sure “Map” is checked and that db_owner is checked under “Database role membership”.
If does NOT exist: Right click Logins -> New Login…
Type: Windows Authentication
Login Name: chose a domain account that has access to both the publisher and distributor server
User Mapping: [your publication database] -> Make sure “Map” is checked and that db_owner is checked under “Database role membership”.
Connect to Distributor:
Repeat all steps above for the [distribution] database
If Log Reader Agent is Local Windows Account (non-domain):
Make sure that you can successfully sign into Windows on both the Publisher server and the Distributor Server with each account AND that they both have the same password. (If passwords are different, passthrough authentication will not work).
Connect to Publisher:
Check: Object Explorer -> Security -> Logins
If already DOES exists: Right click login -> properties -> User Mappings -> [your publication database] -> Make sure “Map” is checked and that db_owner is checked under “Database role membership”.
If does NOT exist: Right click Logins -> New Login…
Type: Windows Authentication
Login Name: chose a local account that on both the publisher and distributor server (and has the same password)
User Mapping: [your publication database] -> Make sure “Map” is checked and that db_owner is checked under “Database role membership”.
Connect to Distributor:
Repeat all steps above for the [distribution] database
For more information about replication security and required permissions, see the official Microsoft docs page: Replication Agent Security Model
The “UDL Test” is a quick, easy, and flexible way to test connectivity to Microsoft SQL Server using a variety of installed providers/drivers using either Windows or SQL Authentication.
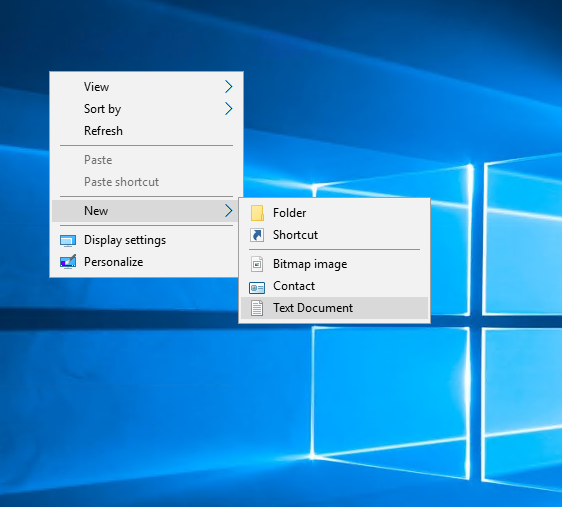
To get started, simply create a new text file on your desktop and give it a name:
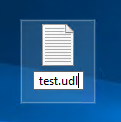
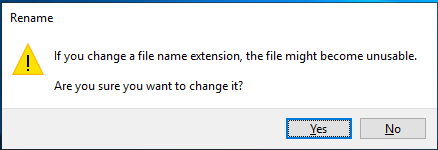
Change the file extension to udl:
You will get this warning:
Click Yes.
The icon should change:
Now just double click to launch:
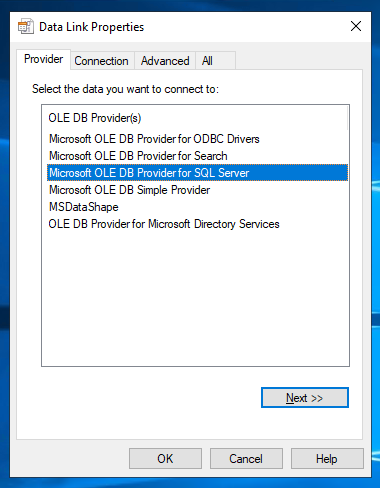
By default the Microsoft OLEDB Provider for SQL Server is specified but you can change the provider you want to use under the Provider tab:
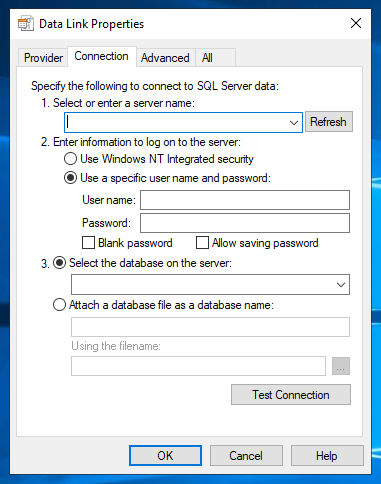
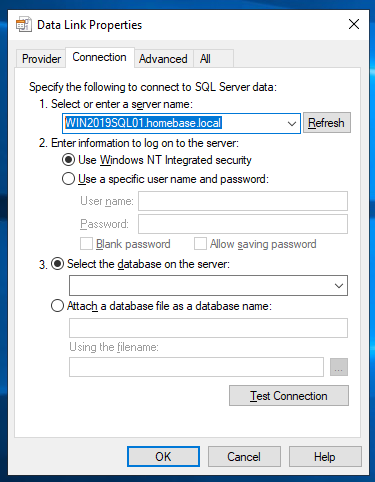
Under the Connection tab, specify the server name and credentials you want to use to connect to either a local or remote SQL Server instance:
NOTE: If you select "Windows NT Integrated security" the User name and password fields are greyed out. This is because the connection will use a token from the Windows account you are currently signed in with.
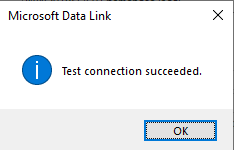
Lastly, click Test Connection and you should see either a “Test connection succeeded.” or “Test connection failed” pop-up:
NOTE: If you click the drop down for "Select the database on the server" this instantly tries to form a connection to master in order to return a list of available databases.
Too often, technical documentation makes too many assumptions about prior knowledge of terminology and standards for beginners to comfortably get started. So, to kick off this learning series, let’s go over some of the terminology and concepts we will be using when learning about SQL Server.
NOTE: Even if you are an experienced database professional or programmer, I encourage you to review this article anyway because identical terminology is often used across different RDBMS with not identical meaning.
Microsoft SQL Server
Relational Database Management System (RDBMS)
SQL Server is one of many Relational Database Management Systems on the market such as Oracle, PostgreSQL, Azure, Azure SQL Database, MySQL, etc. The Relational Database Management System manages all of the databases, data, transactional integrity, security, user access, etc. Other data storage and processing models have become increasingly popular over the years but RDBMS are still widely used for data warehouse projects, business intelligence and more.
SQL Server Business Intelligence (BI)
SQL Server Integration Services (SSIS)
Integration Services at its core is used to perform ETL for a data warehouse. ETL is an industry term that stands for Enhance, Transform, Load. Basically moving data between one database and another. The databases don’t need to be on the same platform either, they can be SQL Server databases, flat files or other database platforms such as Oracle, DB2, Access, Sybase, PostgreSQL, cloud, etc.
SQL Server Reporting Services (SSRS)
Reporting Services provides a set of on-premises tools and services that create, deploy, and manage mobile and paginated reports from Microsoft SQL Server. It is not uncommon for SSRS to be installed on a different machine from the SQL Server Database Engine instance it services.
SQL Server Analysis Services (SSAS)
A typical implementation workflow includes installing a SQL Server Analysis Services instance, creating a tabular or multidimensional data model, deploying the model as a database to a server instance, processing the database to load it with data, and then assigning permissions to allow data access. When ready to go, the data model can be accessed by any client application supporting Analysis Services as a data source.
Power BI
Power BI is a business analytics service. It aims to provide interactive visualizations and business intelligence capabilities with an interface simple enough for end users (Those who aren’t developers or DBAs) to create their own reports and dashboards.
NOTE: I think it is important to mention the SQL BI products now so that you can begin to understand how they fit into the overall eco system. However, this learning series will focus on the SQL Server Database Engine.
SQL Server Database Engine
Microsoft SQL Server originally created as a variant of Sybase SQL Server for IBM OS/2 and released in 1989. Since then there have been numerous releases but as of this writing the most recent (and still actively supported) versions are SQL Server 2012, 2014, 2016, 2017, and 2019.
The product names for SQL Server are denoted by the year of their release. The major version is often referenced in code and configuration metadata as a two to three digit number following this scheme:
Product Name
Major Version
RTM Build Number
SQL Server 2019
150
15.0.2000.5
SQL Server 2017
140
14.0.1000.169
SQL Server 2016
130
13.00.1601.5
SQL Server 2014
120
12.00.2000.8
SQL Server 2012
110
11.00.2100.60
SQL Server 2008 R2
100
10.50.1600.1
SQL Server 2008
100
10.00.1600.22
SQL Server 2005
90
9.00.1399.06
SQL Server 2000
80
8.00.194
Notice that the major version and build number correlate as well.
As a beginner the term “SQL Server” may seem confusing because it is often used to mean different things in different contexts including: the physical hardware server, the application, or the database engine. To clarify, when I reference SQL Server in my posts I am referencing the database engine. If I am referencing the software product I will use the full product name which is “Microsoft SQL Server”. If I am referring to the machine which hosts a SQL Server Instance, I will say some variation of “SQL Machine”, “SQL Node”, “SQL Host”, “SQL VM”, “SQL Box”, ect.
On Premises vs. Cloud
NOTE: For this learning series I will be focusing mostly on Microsoft SQL Server On Premises.
On Premises
Microsoft SQL Server was originally and still is developed as an On Premises (abbreviated as On Prem) software product meaning that it is installed on hardware owned and managed by you or your organization on a physical or virtual machine with an operating system (Windows or Linux).
Cloud: Azure SQL Product Family
With the rise of the enterprise cloud, Microsoft began offering different flavors of Microsoft SQL Server in Azure. Each has its own advantages/disadvantage and level of tradeoff between administration/management responsibilities and freedom/flexibility. These offerings include:
SQL Server on Azure Virtual Machines*
Azure SQL Managed Instance
Azure SQL Database
Azure SQL Edge
NOTE: While hosted in the cloud, SQL Server on Azure VMs is the same On Prem Microsoft SQL Server product, just installed on a virtual machine running in Azure instead of on your own machine.
SQL Server Instance
A SQL Server instance is a single installation of the SQL Server software. This instance encapsulates all the other database system structures (database, tables, data, stored procedures, security, ect.)
A given physical server can host or have installed multiple instances of SQL Server of either the same or different versions. (Although certain components are shared between them but more on that later).
Often you will have multiple instances of SQL Server installed either on the same machine or on different machines supporting the same connected application(s) to be used for Production (PROD), Quality Assurance (QA), Testing (TEST), User Acceptance Testing (UAT), and/or Development (DEV).
SQL Server Services
SQL Server components are executable programs that run as a Windows service. Programs that run as a Windows service can continue to run even without a user actively logged in and without displaying a window or other activity in the GUI.
SQL Server Service
The executable process that is the SQL Server Database Engine. The Database Engine can be the default instance (limit one per computer) or can be one of many named instances of the Database Engine. Use SQL Server Configuration Manager to determine which instances of the Database Engine are installed on the computer. The default instance (if you install it) is listed as SQL Server (MSSQLSERVER). Named instances (if you install them) are listed as SQL Server (<instance_name>). By default, SQL Server Express is installed as SQL Server (SQLEXPRESS).
SQL Server Agent
This is a job scheduling service. It connects to the SQL Server instance and executes jobs defined by the user either on demand, on startup or by a user defined schedule. This service is not strictly necessary for SQL Server operation and is actually not included in the Express Edition of SQL Server.
SQL Server Browser
Shared and used by all installed instances of SQL Server on a given machine. It is responsible for responding to incoming requests with client information for connecting to SQL Server. This service can be disabled if the only instance in use is the default instance (MSSQLSERVER) and it is running on the default static port (TCP 1433).
Host/Box/Physical Machine/Bare Metal
The hardware platform (i.e. server) with the virtualization software to support one or many Guest virtual machines. The host may also have SQL Server installed directly on it without any virtualization.
Virtual Machine (VM)
A virtual environment that functions as a virtual computer system with its own CPU, memory, network interface, and storage, simulated on physical hardware (host).
Hyper Visor/ Virtual Machine Monitor (VMM)
The software application running on the host that is responsible for managing one or more virtual machines.
Database
The logical container for stored data. It encapsulates all the other data structures.
System Databases
System database
Description
master Database
Records all the system-level information for an instance of SQL Server.
msdb Database
Is used by SQL Server Agent for scheduling alerts and jobs.
model Database
Is used as the template for all databases created on the instance of SQL Server. Modifications made to the model database, such as database size, collation, recovery model, and other database options, are applied to any databases created afterward.
Resource Database
Is a read-only database that contains system objects that are included with SQL Server. System objects are physically persisted in the Resource database, but they logically appear in the sys schema of every database.
tempdb Database
Is a workspace for holding temporary objects or intermediate result sets.
User Databases
All other databases created on a given instance of SQL Server. Each of which has a unique name and an owner. The User Defined database has one or more schemas and each schema has tables, indexes, stored procedures, views, functions and more.
Database Files
SQL Server databases have three types of files, as shown in the following table.
File
Description
Primary
Contains startup information for the database and points to the other files in the database. Every database has one primary data file. The recommended file name extension for primary data files is .MDF.
Secondary
Optional user-defined data files. Data can be spread across multiple disks by putting each file on a different disk drive. The recommended file name extension for secondary data files is .NDF.
Transaction Log
The log holds information used to recover the database. There must be at least one log file for each database. The recommended file name extension for transaction logs is .LDF.
Note that while the .MDF, NDF and LDF file extensions are recommended, you can technically make them whatever you want, but as a Support Engineer I beg you not to.
Schema
A schema is a logical container within a database to grant permissions to particular objects. By default, each SQL Server database has a dbo and sys schema. Although user defined objects can be created in the dbo schema, it is generally recommended to create a separate schema for each logical application such as sales, inventory, accounting, etc.
Table
Tables are database objects that contain all the data in a database. In tables, data is logically organized in a row-and-column format similar to a spreadsheet. In fact, a spreadsheet can be thought of as a “flat” database whereas SQL Server is a “relational database” because it is modeled around the relationships between tables.
A table is a collection of zero or more rows where each row is a sequence of one or more column values.
Row
The row is the smallest unit of data that can be inserted into a table and deleted from a table.
Cardinality
The degree of a table, and the degree of each of its rows, is the number of columns of that table. The number of rows in a table is its cardinality. A table whose cardinality is 0 (zero) is said to be empty.
Transactional Structured Query Language (T-SQL)
A set of programming extensions from Sybase and Microsoft that add several features to the Structured Query Language (SQL), including transaction control, exception and error handling, row processing and declared variables.
Constraints
Constraints are the rules enforced on the data columns of a table. These are used to limit the type of data that can go into a table.
Referential Integrity
Although the main purpose of a foreign key constraint is to control the data that can be stored in the foreign key table, it also controls changes to data in the primary key table. To successfully change or delete a row in a foreign key constraint, you must first either delete the foreign key data in the foreign key table or change the foreign key data in the foreign key table, which links the foreign key to different primary key data.
Primary Key (PK)
A table typically has a column or combination of columns that contain values that uniquely identify each row in the table. This column, or columns, is called the primary key (PK) of the table and enforces the entity integrity of the table.
Foreign Key (FK)
A foreign key (FK) is a column or combination of columns that is used to establish and enforce a link between the data in two tables to control the data that can be stored in the foreign key table. In a foreign key reference, a link is created between two tables when the column or columns that hold the primary key value for one table are referenced by the column or columns in another table. This column becomes a foreign key in the second table.
Indexes (IX)
An index is an on-disk structure associated with a table or view that speeds retrieval of rows from the table or view. An index contains keys built from one or more columns in the table or view. These keys are stored in a structure (B-tree) that enables SQL Server to find the row or rows associated with the key values quickly and efficiently.
Heap
A heap is a table without a clustered index. One or more nonclustered indexes can be created on tables stored as a heap. Data is stored in the heap without specifying an order. Usually data is initially stored in the order in which is the rows are inserted into the table, but the Database Engine can move data around in the heap to store the rows efficiently; so the data order cannot be predicted.
Clustered Index (CI)
A clustered index sorts and stores the data rows of the table or view in order based on the clustered index key. The clustered index is implemented as a B-tree index structure that supports fast retrieval of the rows, based on their clustered index key values.
Non Clustered Index (NCI)
A nonclustered index can be defined on a table or view with a clustered index or on a heap. Each index row in the nonclustered index contains the nonclustered key value and a row locator. This locator points to the data row in the clustered index or heap having the key value. The rows in the index are stored in the order of the index key values, but the data rows are not guaranteed to be in any particular order unless a clustered index is created on the table.
Query
A query is a question or inquiry about a set of data. In SQL Server we use T-SQL to retrieve meaningful and relevant information from databases. When building a structure, we pull data from tables and fields. The fields are columns in the database table, while the actual data makes up the rows.
Store Procedure (SP)
A stored procedure in SQL Server is an executable object that consists of a group of one or more Transact-SQL statements or a reference to a Microsoft .NET Framework common runtime language (CLR) method. They can accept input parameters, call other stored procedures, and return success/failure messages.
Common Language Runtime (CLR)
With the CLR hosted in Microsoft SQL Server (called CLR integration), you can author stored procedures, triggers, user-defined functions, user-defined types, and user-defined aggregates in managed code. Because managed code compiles to native code prior to execution, you can achieve significant performance increases in some scenarios.
Ad Hoc Query
Ad hoc is Latin for “for this purpose”. Sometimes ad hoc queries may be informally referred to as “on the fly” because unlike stored procedures they are not predefined. Queries such as SELECT * FROM sys.databases is an example of an Ad hoc query that you may issue from SSMS. However, they can also be dynamically generated by code on the application side and executed against SQL Server.
Data Manipulation Language (DML)
These are statements used to retrieve and work with data. Microsoft SQL Server uses the following DML statements:
These are statements that define data structures. Use these statements to create, alter, or drop data structures in a database. Microsoft SQL Server uses the following DDL statements:
These statements are used for access control and permission management for users in the database. Use these statements to allow or deny some actions for users on the tables or records. Microsoft SQL Server uses the following DCL statements:
These statements are used for managing transactions in the database. Use these to manage the transactions that are performed by DML statements. Microsoft SQL Server uses the following TCL statements:
A stored program that you can pass parameters into and return a value, much the same as in any programming language.
View
A view is a virtual table whose contents are defined by a query. Like a table, a view consists of a set of named columns and rows of data. You can think of it as instructions for how to piece together two tables temporarily. If not indexed, the view does not persist as stored data (i.e. will be discarded then generated again the next time it is used)
Triggers
A mechanism which fires a particular stored procedure in response to an event.
Logon Triggers
Logon triggers fire stored procedures in response to a LOGON event. This event is raised when a user session is established with an instance of SQL Server.
DDL Trigger
DDL triggers fire in response to a variety of Data Definition Language (DDL) events. These events primarily correspond to Transact-SQL statements that start with the keywords CREATE, ALTER, DROP, GRANT, DENY, REVOKE or UPDATE STATISTICS.
DML Trigger
DML triggers is a special type of stored procedure that automatically takes effect when a data manipulation language (DML) event takes place that affects the table or view defined in the trigger. DML events include INSERT, UPDATE, or DELETE statements. DML triggers can be used to enforce business rules and data integrity, query other tables, and include complex Transact-SQL statements.
Tools
Below are some of the tools that are commonly used when interacting with Microsoft SQL Server.
SQL Server Management Studio (SSMS)
Manage a SQL Server instance or database with full GUI support. Access, configure, manage, administer, and develop all components of SQL Server, Azure SQL Database, and Azure Synapse Analytics. Provides a single comprehensive utility that combines a broad group of graphical tools with a number of rich script editors to provide access to SQL for developers and database administrators of all skill levels.
Azure Data Studio
A light-weight editor that can run on-demand SQL queries, view and save results as text, JSON, or Excel. Edit data, organize your favorite database connections, and browse database objects in a familiar object browsing experience.
SQL Server Data Tools (SSDT)
A modern development tool for building SQL Server relational databases, Azure SQL databases, Analysis Services (AS) data models, Integration Services (IS) packages, and Reporting Services (RS) reports. With SSDT, you can design and deploy any SQL Server content type with the same ease as you would develop an application in Visual Studio.
SQLCMD
A utility lets you enter Transact-SQL statements, system procedures, and script files at the command prompt.
SQL Server Powershell
Provides cmdlets for working with SQL.
SQL Server Configuration Manager
Use SQL Server Configuration Manager to configure SQL Server services and configure network connectivity. Configuration Manager runs on Windows.
NOTE: See here for a more comprehensive and current list of Microsoft SQL Server first party tools.
Summary
This introduction to the series is by no means meant to be a comprehensive overview of the SQL Server product, but more of primer to familiarize you with some of the concepts and terminology before we dive deeper. In the next post we will introduce the Transactional SQL (T-SQL) language and the anatomy of transactions.
There might be times that you need to backup or restore databases in MSSQL Server to a network location. Out of the box, this isn’t the easiest thing to do. So I will show you the steps you can take to successfully backup and restore databases to and from network mapped drives.
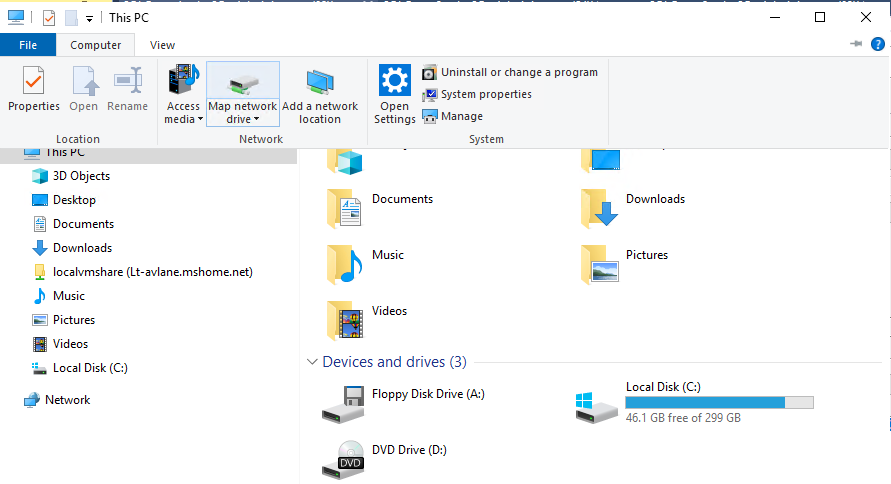
Start by mounting a network drive (optional):
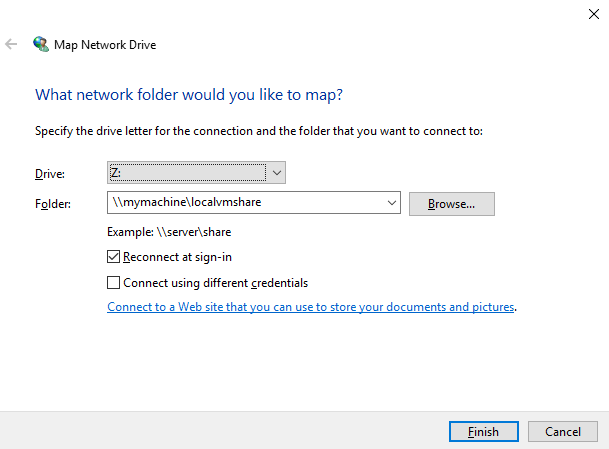
Enter the path for the network drive and click Next:
You will be prompted to enter credentials, do so then Finish
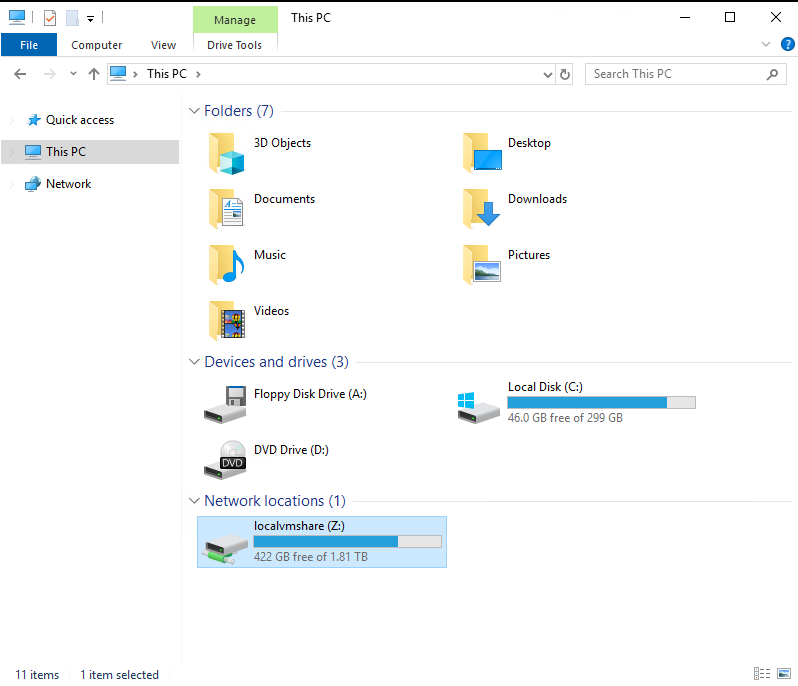
You’ll now see a new drive under Network Locations with your given drive letter:
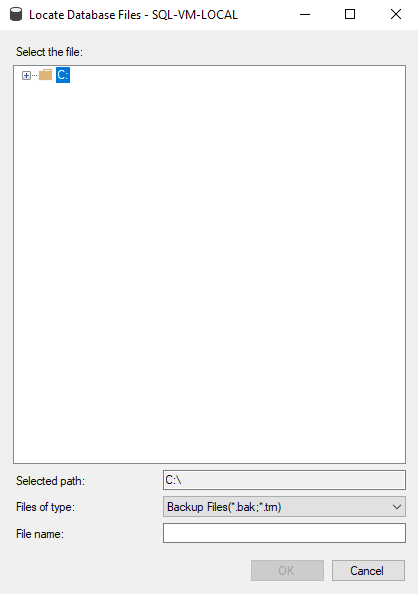
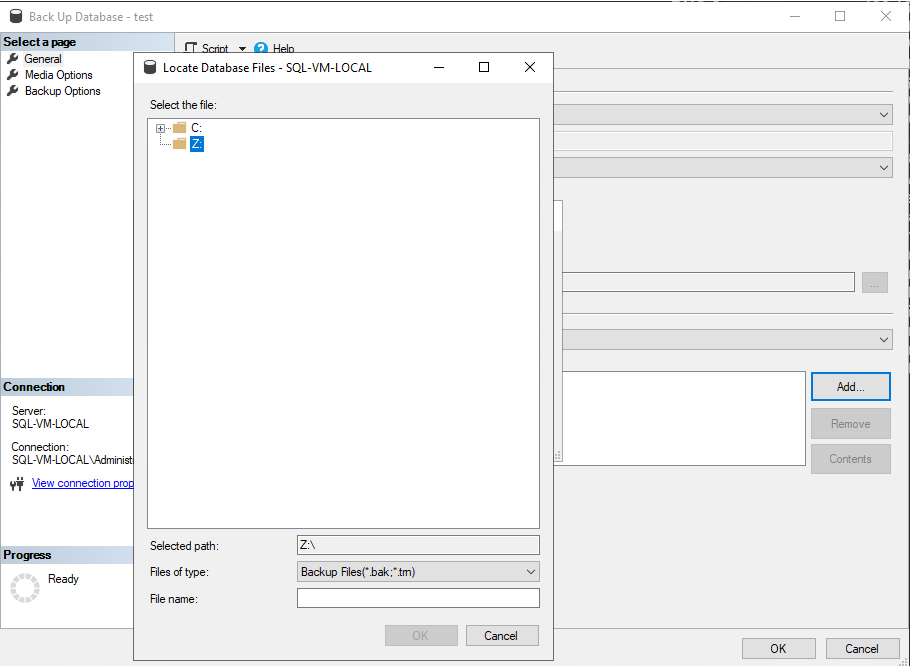
However, if you go to SSMS and try to backup a database via the GUI you won’t be able to see the drive letter:
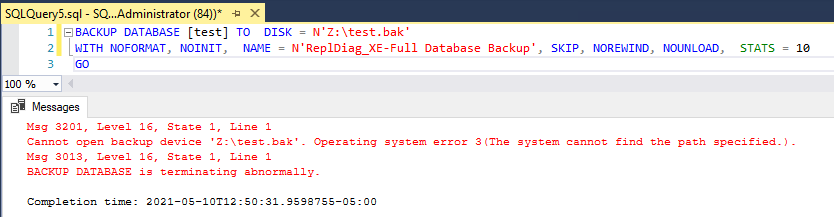
If you try to do it via script instead, you’ll get an operating system error:
Msg 3201, Level 16, State 1, Line 1
Cannot open backup device ‘Z:\test.bak’. Operating system error 3(The system cannot find the path specified.).
Msg 3013, Level 16, State 1, Line 1
BACKUP DATABASE is terminating abnormally.
This is because SQL Server is registered and running as a service running under the context of the SQL Server service account. The service runs in the environment of the local console with the security of this service account. Network mapped drives are specific to a session and not visible to services started on the local console.
So how do we work around this? By using XP_CMDSHELL.
First, make sure XP_CMDSHELL is enabled:
EXEC sp_configure 'show advanced options', 1;
GO
RECONFIGURE;
GO
EXEC sp_configure 'xp_cmdshell',1
GO
RECONFIGURE
GO
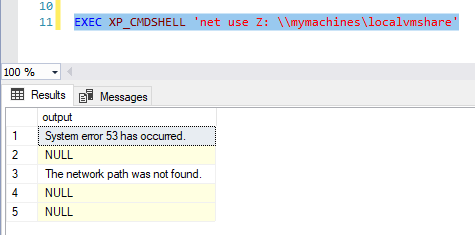
Next, use the following command, replacing Z: \\mymachine\localvmshare with your own network path:
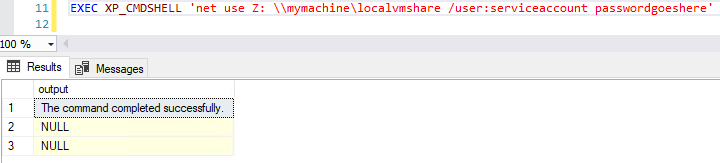
EXEC XP_CMDSHELL 'net use Z: \\mymachine\localvmshare'
The drive should now be mapped. You can test that it is properly mapped with the following:
EXEC XP_CMDSHELL 'Dir Z: '
If you mistype the path you might see an error like these:
System error 53 has occurred. The network path was not found.
If you get this error just correct the typo and run the command again.
NOTE: To remove the mapping once you are done with it, or to remove a mapping that was mistyped, you can run the following command: EXEC XP_CMDSHELL 'net use Z: /delete'
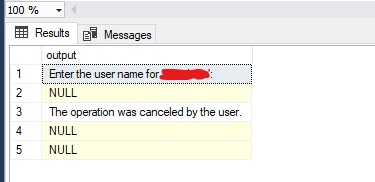
Another error you could possibly get is this one:
Enter the user name for ‘mymachine’:
The operation was canceled by the user.
If this occurs, modify the XP_CMDSHELL statement like so, where serviceaccount is a user that has permission to mount the network drive and passwordgoeshere is the password for the user account:
Now, in the GUI, we should be able to see our newly mapped drive in the backup/restore wizard:
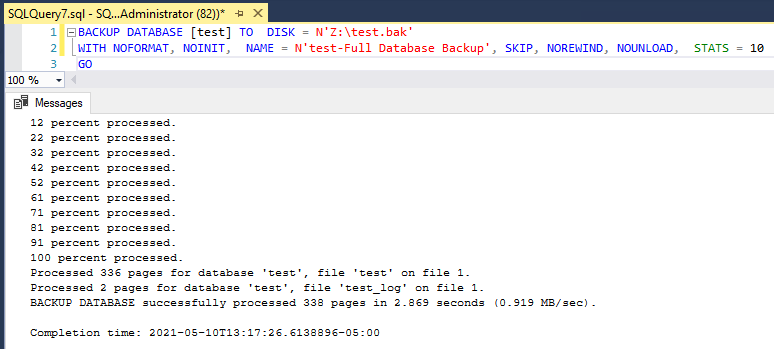
If we rerun our script to backup, it is now successful:
And there is our backup file:
NOTE: The next time the SQL Server Service is restarted, the mapping will be removed and if you have automated backup jobs configured to use these drives, they will fail. If you decide to rely on this method for network drive backups, you will need to add logic to your backup jobs to check that the drive mapping exists first or you will need to have a startup proc configured to run and map the drive on restart.
In the case of the client I was working with, we needed to setup database mirroring via backup and restore but the local machine did not have enough disk space free to accommodate the backups. However, it is work noting that XP_CMDSHELL is a powerful feature that runs under the context of the SQL Server service account. Malicious users sometimes attempt to elevate their privileges by using XP_CMDSHELL so you should keep this in mind when deciding if you should use XP_CMDSHELL in your maintenance/backup strategy on a permanent basis.
Microsoft SQL Server is a Service that runs inside of an OS (no longer exclusively on Windows – i.e. SQL Server on Linux). However, it has its own mechanisms for handling memory management, IO and thread scheduling. This is done through access to the host OS API in most cases, but SQL is still the one actively managing these resources.
Thread
A thread is the basic unit to which the operating system allocates processor time. A thread can execute any part of the process code, including parts currently being executed by another thread. Threads are the smallest units of processing that can be executed by an operating system, and allow the application logic to be separated into several concurrent execution paths.
SQL Server Worker Thread
Also known as worker or thread, is a logical representation of an operating system thread. When executing serial requests, the SQL Server Database Engine will spawn a worker to execute the active task (1:1).
Process
When an operating system executes an instance of an application, it creates a unit called a process to manage the instance. The process has a thread of execution. This is the series of programming instructions performed by the application code.
Request
In the scope of SQL Server, a request is the logical representation of a query or batch. A request also represents operations required by system threads, such as checkpoint or log writer. Requests exist in various states throughout their lifetime and can accumulate waits when resources required to execute the request are not available, such as locks or latches.
Task
A task represents the unit of work that needs to be completed to fulfill the request. One or more tasks can be assigned to a single request.
Scheduler
A scheduler, also known as SOS scheduler (meaning SQL OS scheduler but never actually referred to as such), manages worker threads that require processing time to carry out work on behalf of tasks.
Quantum
The amount of time that a thread is permitted to run on the processor before it must yield to another thread and return to the Runnable Queue or the Wait List.
Scheduler Components
At a high and somewhat abstracted level, schedulers have three main components: the Processor, Waiter List and Runnable Queue.
The Processor is the logical processor core which processes the threads one at a time. Each scheduler is mapped to a single processor.
The Waiter List represents the list of threads that are waiting for resources (such as latches and locks).
The Runnable Queue represents the group of threads that are not waiting on resources (as they have already acquired them) and are instead are waiting for their turn to run on a processor.
The thread of a process will move between these three states as they get executed. The threads are always either doing work on the processor, waiting for a particular resource, or they have a resource and are waiting in line to run on the processor again. Once a thread is running on the processor, it will continue to do so until either it has finished its work and needs to again wait for another resource OR it reaches its maximum allotted time on the processor (called the OS quantum). This Quantum value is 4ms is non configurable.
Thread States
At any given time a thread can be in one of three states: RUNNING, SUSPENDED, or RUNNABLE.
RUNNING is the state where the thread is actually executing on the processor and utilizing CPU spins. Only one thread per scheduler can have this state at a time.
During execution, if the thread needs to wait for a particular resource in SQL (such as a lock or latch), it yields its time on the processor and moves to the Waiter List. When here the state of the thread changes to SUSPENDED while it waits for the resource to be acquired.
Once the resource has been acquired the thread is again ready to use the processor again but must wait its turn behind the other threads waiting to execute so it moves to the Runnable Queue and its state is changed to RUNNABLE.
NOTE:
If a RUNNING thread reaches the end of its 4ms quantum and doesn't need to wait to acquire another resource, voluntarily yields for the next thread and enters the Runnable Queue where its state changes back to RUNNABLE.
This dance continues until the thread(s) complete all the work assigned to them. This is called cooperative or non-preemptive scheduling. It relies on all of the processes at play voluntarily yielding when they are supposed to. For a comparison see this post on Preemptive vs Cooperative Multitasking.
As of the writing of this post, when creating extended events sessions in SQL Server Management Studio (SSMS), on the Set Session Event Filters page of the New Session Wizard, there is an option to include events that are like a specified value (using the like_i_sql_unicode_string operator) but there is not currently anything in the GUI to EXCLUDE queries that meet this filter criteria.
Adding a “NOT LIKE” clause to the extended events filter seems to be a limitation of the GUI currently. The steps below show you how to select all of your extended events via the wizard and then add the “NOT LIKE” functionality at the end by scripting out the Extended Event and making a minor tweak.
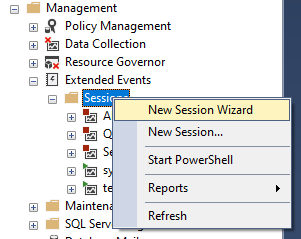
Open the New Session Wizard in SSMS:
Give it a name
Select “Do not use a template” and click Next
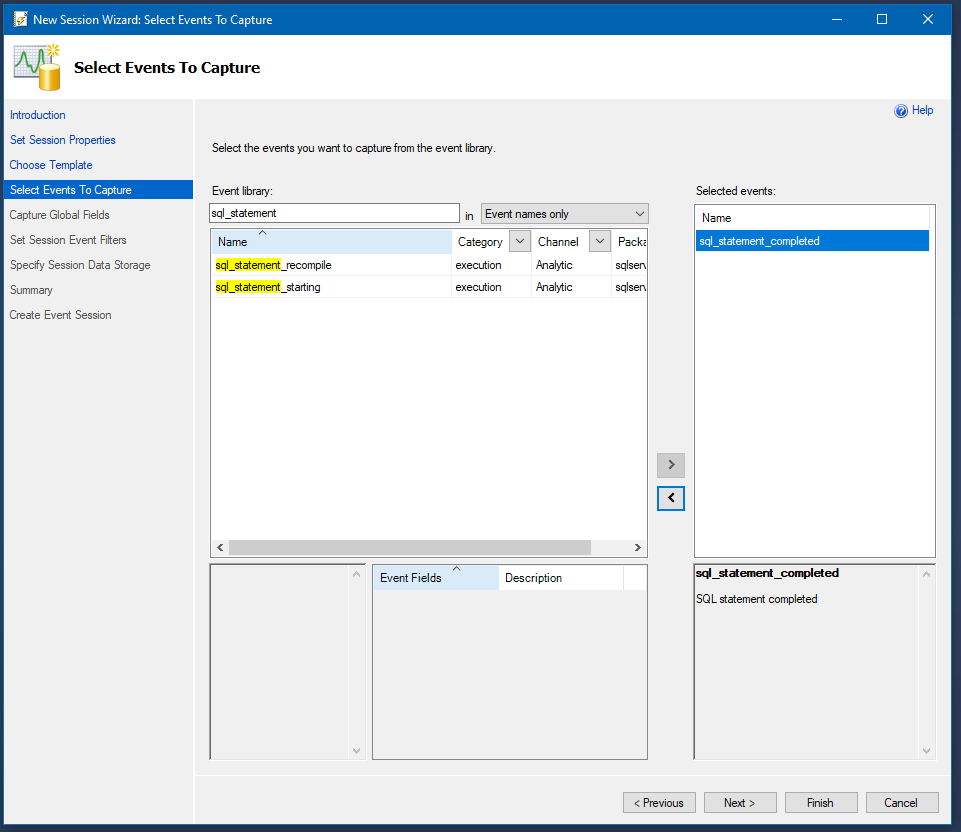
Search for sql_statement_completed in the list and add it to the Selected Events and click Next
On the Capture Global Fields page, click Next
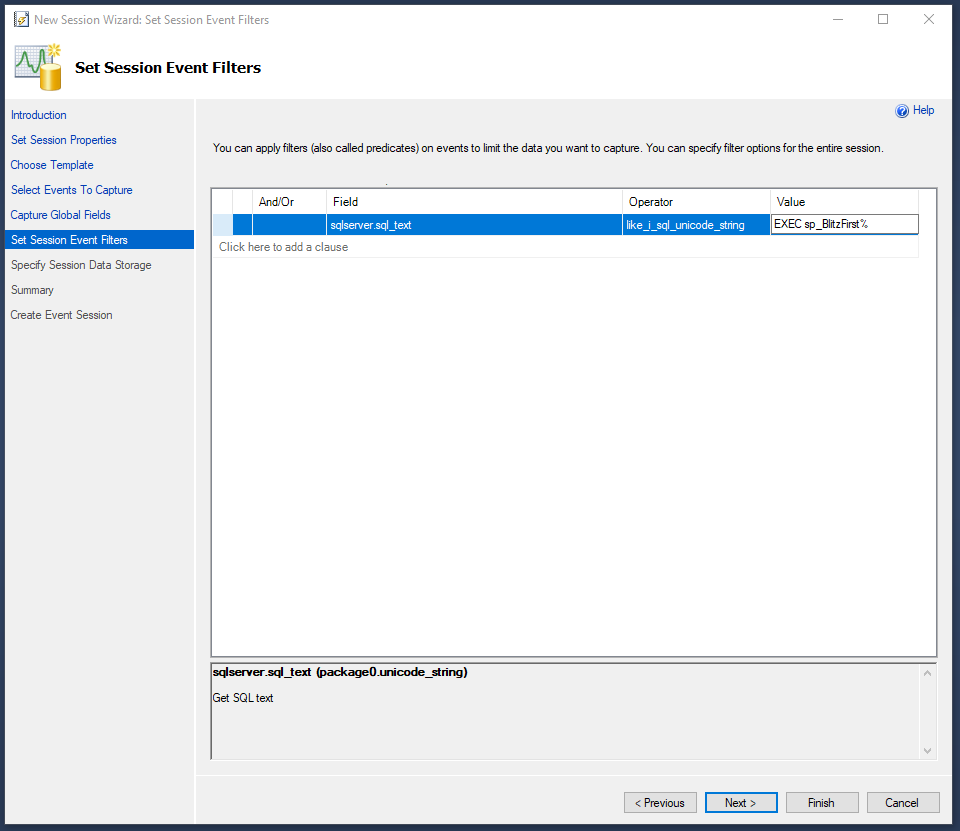
On the Set Session Event Filters page, select “sqlserver.sql_text from the “Field” drop down list and set the “Operator” to like_i_sql_unicode_string and set the “value” field to the full or partial sql query that you would like to exclude. Then click next.
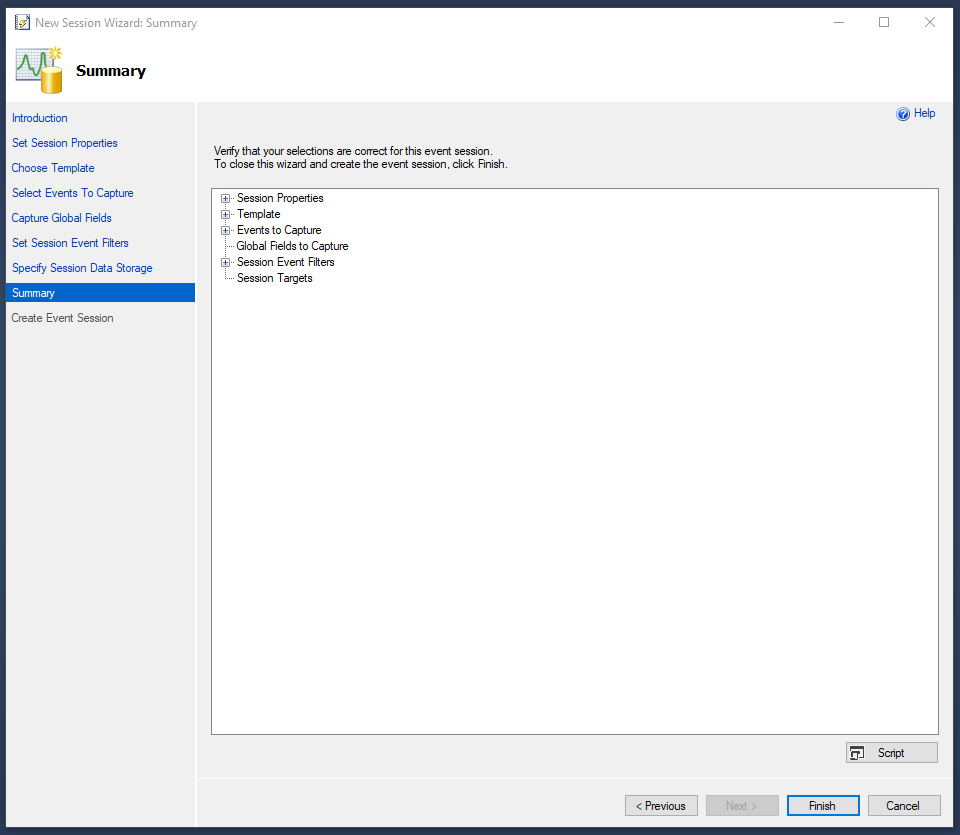
Continue to the Summary page of the wizard and click on the “Script” button
You should see a script like this:
We’re almost there but this script in its current form will do the opposite of what we want. This script will capture ONLY the sp_BlitzFirst execution. To have it exclude these executions, we have to make the following change:
Here is the TSQL text from this proof of concept:
CREATE EVENT SESSION [XEventFilterTest] ON SERVER
ADD EVENT sqlserver.sql_statement_completed(
WHERE ( NOT [sqlserver].[like_i_sql_unicode_string]([sqlserver].[sql_text],N'EXEC sp_BlitzFirst%')))
WITH (STARTUP_STATE=OFF)
GO
Other Notes:
The total number of characters allowed for ALL filters on an event is 3,000. If you execeed this threshold, you may see an error that resembles the following:
Msg 25716, Level 16, State 1, Line 1
The predicate on event, "sqlserver.attention", exceeds the maximum length of 3000 characters.
To workaround this issue, split your Extended Events Session into multiple sessions.
I was recently working with a client that was periodically but inconsistently getting a strange error when one of their SQL Server Agent jobs ran:
ERROR: CREATE TABLE permission denied in database 'tempdb'
Why is this error confusing? Well, at a minimum every database and every user has at least the public role. The public role is contained in every database, which includes system databases. It cannot be dropped and you cannot add or remove users from it. Permissions granted to the public role are inherited by all other users and roles because they belong to the public role by default.
We also know that any user with the public role can create temporary tables in tempdb. So, how on earth does this error make any sense?
Let me demonstrate.
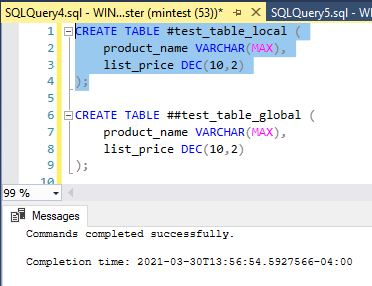
It is still true that with only the public role a user can create both local and global temporary tables.
If you want to demonstrate this, create a new user in SQL and make sure that it only has the public role then try to create some tables like below:
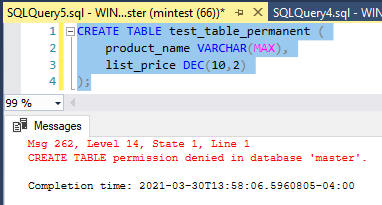
So, as you can see, the original statement is still true. The public role allows users to create temp tables in tempdb without any additional permissions. However, to create permanent tables in tempdb you will still need the CREATE TABLE permission.
In my client’s case it was a matter of a simple typo. One particular code path in the SQL Agent job triggered a code path containing the typo where a CREATE TABLE statement was missing a ‘#’ in front of the table name.
If you’re wondering why you would create a “permanent” table in tempdb, you wouldn’t in most cases but it does have some unique properties in that the table is available from other sessions (unlike local temporary tables), and it is not deleted automatically even if there are no connections to it (unlike global temporary tables). However, it does still get deleted when the instance is restarted (just like everything else in tempdb).
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies. You can review our cookie policy here.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.