A Queue is a FIFO (First In First Out — the element placed at first can be accessed at first) structure which can be commonly found in many programming languages. This structure is named as “queue” because it resembles a real-world queue — people waiting in a queue (line).
Just like in like real life, the person who was in line first gets served first.
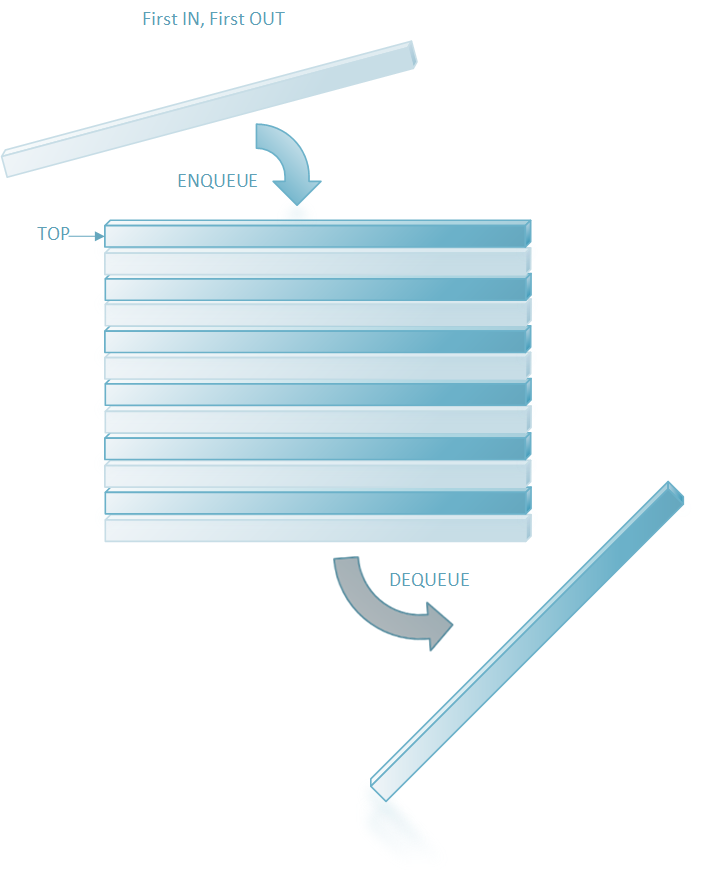
Diagram: Queue
Queue Operations
Given below are the 2 basic operations that can be performed on a queue. Reference the diagram above
Enqueue: Insert an element to the end of the queue.
Dequeue: Delete the element from the beginning of the queue.
Applications of Queues
Used to manage threads in multithreading.
Used to implement queuing systems (e.g.: priority queues).
A Stack is a linear data structure which follows a particular order in which the operations are performed. The order may be LIFO (Last In First Out) or FILO (First In Last Out).
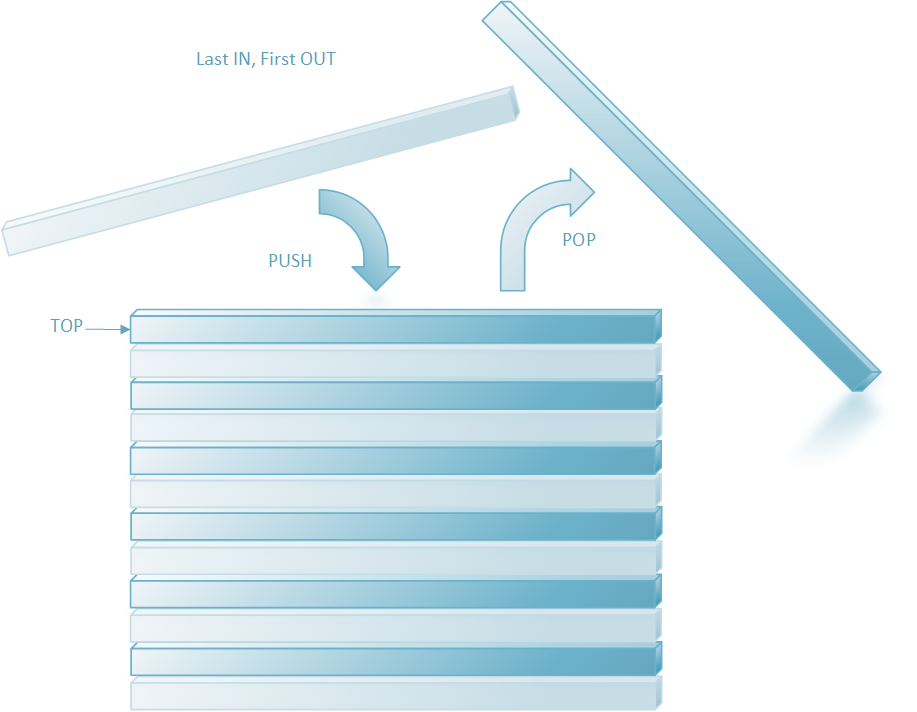
Diagram: Stack
Push: Insert an element on to the top of the stack.
Pop: Delete the topmost element and return it.
Furthermore, the following additional functions are provided for a stack in order to check its status.
Peek: Return the top element of the stack without deleting it.
isEmpty: Check if the stack is empty.
isFull: Check if the stack is full.
Applications of stacks
Used for expression evaluation (e.g.: shunting-yard algorithm for parsing and evaluating mathematical expressions).
Used to implement function calls in recursion programming.
An array is a collection of items stored at contiguous memory locations. The idea is to store multiple items of the same type together. This makes it easier to calculate the position of each element by simply adding an offset to a base value, i.e., the memory location of the first element of the array.
Diagram: Array
The diagram above demonstrates how each element can be uniquely identified by its index value or by its memory address. Notice that the memory addresses are sequential. This is what is meant by contiguous (touching). This demonstrates how and why order is preserved with arrays.
A Doubly Linked List (DLL) is very similar to a Linked List, but contains an extra pointer, typically referred to as previous pointer, together with next pointerand the data.
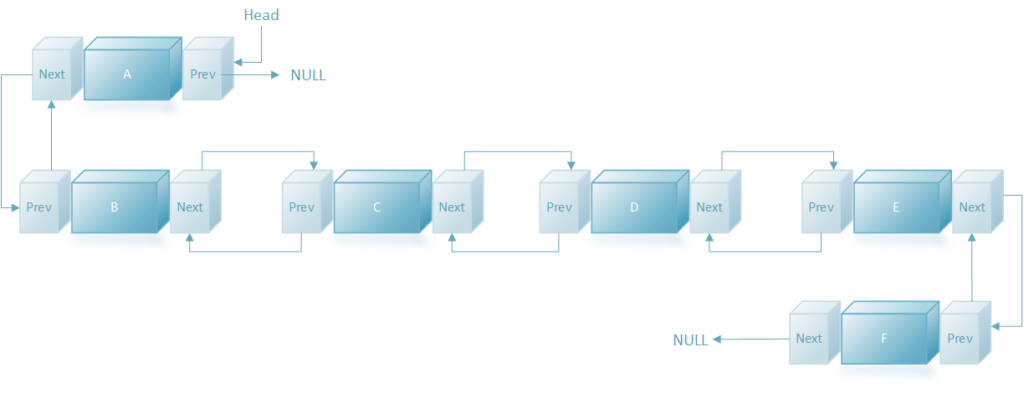
Diagram: Doubly Linked List
Advantages over singly linked list
A doubly linked list can be traversed in both forward and backward direction.
The delete operation for doubly linked lists is more efficient if pointer to the node to be deleted can be supplied.
Quickly insert a new node before a given node.
In a singly linked list, to delete a node, the pointer to the previous node is needed. To get the previous node, the list has to be traversed from the beginning. Whereas the doubly linked list can fetch the previous node using previous pointer.
DisadvantageS
Every node of the doubly linked list requires extra space for the previous pointer.
All operations have additional overhead because of the extra previous pointer. For example, in insertion, we need to modify previous pointers together with next pointers.
Like arrays, the Linked List is a linear data structure. Unlike arrays, linked list elements are not stored at a contiguous location; the elements are linked using pointers.
Like arrays, the Linked List is a linear data structure. Unlike arrays, linked list elements are not stored at a contiguous location; the elements are linked using pointers.
Diagram: Linked List
Why use a Linked List over an Array?
Arrays can be used to store linear data of similar types, but arrays have the following limitations: 1) Arrays have a fixed size – so we must know the upper limit (ceiling) on the number of elements in advance. Additionally, in most implementations, the memory allocation is equal to the upper limit regardless of usage. 2) Inserting new elements into an array is expensive because space has to be created for the new elements and to create space, existing elements have to be shifted. For example, in a system, if we maintain a sorted list of IDs in an array nums[]. nums[] = [100, 101, 105, 200, 206]. And if we want to insert a new ID 104, then to maintain the sorted order, we have to move all the elements after 100 (excluding 100). Deletion is also expensive with arrays. For example, to delete 101 in nums[], everything after 101 has to be shifted.
Advantages over arrays:
Dynamic size
Ease of insertion/deletion
Disadvantages:
Random access is disallowed. We must access elements sequentially starting from the first node and then traverse the list until we reach the element we are seeking. So an efficient binary search is not an option with linked lists in their default implementation.
The more segments a list is broken into the more overhead there is for locating the next linked element.
Extra memory space for a pointer is required with each element of the list.
Not cache friendly. Since array elements are contiguous locations, there is locality of reference which is not the case for linked lists.
Representation
A linked list is represented by a pointer to the first node of the linked list. The first node is called the head. If the linked list is empty, then the value of the head is NULL. Each node in a list consists of at least two parts: 1) Data 2) Pointer (Or Reference) to the next node
Microsoft SQL Server Always On Availability Groups was introduced in SQL Server 2012 and were a more mature, stable and robust version of database mirroring. In fact, the AG feature was built with mirroring at its foundation. SQL Server 2014 introduced several improvements including increasing the readable secondaries count and sustaining read operations upon secondary-primary disconnections, and it provides new hybrid disaster recovery and backup solutions with Microsoft Azure.
As the feature became more mature and stable I began seeing environments that really pushed the limits of what the technology was capable of.
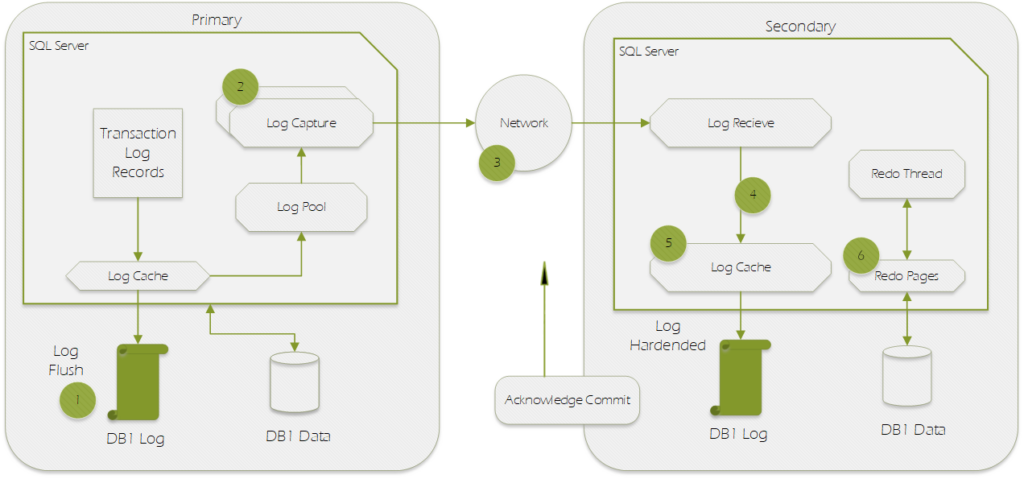
Always On AG Data Synchronization Flow
Always On AG Data Sync Flow
Sequence
Step
Description
1
Log generation
Log data is flushed to disk. This log must be replicated to the secondary replicas. The log records enter the send queue.
2
Capture
Logs for each database is captured and sent to the corresponding partner queue (one per database-replica pair). This capture process runs continuously as long as the availability replica is connected and data movement is not suspended for any reason, and the database-replica pair is shown to be either Synchronizing or Synchronized. If the capture process is not able to scan and enqueue the messages fast enough, the log send queue builds up.
3
Send
The messages in each database-replica queue is dequeued and sent across the wire to the respective secondary replica.
4
Receive and cache
Each secondary replica receives and caches the message.
5
Harden
Log is flushed on the secondary replica for hardening. After the log flush, an acknowledgment is sent back to the primary replica.
Once the log is hardened, data loss is avoided.
6
Redo
Redo the flushed pages on the secondary replica. Pages are kept in the redo queue as they wait to be redone.
The diagram above demonstrates the data movement steps for a simple two node Always On AG with Synchronous Commit Enabled.
Put briefly, a transaction occurs on the Primary and waits (logged as HADR_SYNC_COMMIT waits) while the transaction is sent across the wire to the Secondary replica. The secondary replica hardens the transaction to the log then sends an acknowledgement back to the Primary. Having received confirmation from the secondary that the data is safely committed to the transaction log, the primary can now issue a commit to finish its own transaction and release any locks it may have been holding.
But wait… when exactly does redo occur? Notice that step 6 which involves the redo process is purposefully separated from the rest of the data flow. This is because even when the AG is set to Synchronous Commit, the Redo still occurs asynchronously.
Asynchronous Redo: Potential Impact From Long Failovers and Extended Recovery
Synchronous Commit is a configuration option for Availability Groups but in my opinion it is really more of a Disaster Recovery feature than a High Availability Feature because it’s primary function is to make sure that in the even of a failure of the primary node, failover to a secondary node can occur either manually or automatically with zero data loss (Disaster Recovery) but no guarantees are made about how long it takes to perform the failover (High Availability).
Because we do not commit on the primary until the transaction hardens on the primary, data consistency is guaranteed. However, since changes are applied to the data file from the redo queue on the secondary with no synchronization mechanism to prevent the primary from “getting ahead”, it is possible for the data on the secondaries to lag behind. When this occurs you will see the redo queue grow in size and failovers may take longer than expected. This is because during a failover the secondary database is brought from a Restoring/Synchronizing state to an Online state. Part of the onlining process is the three Recovery steps:
Phase 1: Analysis
Phase 2: Redo
Phase 3: Undo
That’s right, as part of the failover all of the transactions that had been committed but not yet redone must now be redone before the database can come online. The same is true if there is no failover but the local instance is in the Primary role and restarts. This becomes especially burdensome if there are a high number of VLFs which likely means the not yet redone transactions are also heavily fragmented.
Asynchronous Redo: Potential Impact to Readable Secondaries
In addition to impacting failover recovery intervals, there is the potential to impact read-only data consistency. Now that sounds bad, but in my experience the scenario is quite rare. Basically, the issue manifests itself if you have an workflow that performs a DML operation on the primary and then IMMEDIATELY check for the updated row on the secondary. In this scenario it is possible that the transaction has been committed on the primary and hardened to the secondary’s log but not yet redone – leading to what appears to be inconsistent data.
So why not have synchronous redo too? Well, to understand that you need to be familiar with CAP Theorem which basically states you can’t have it all. Between high availability, partitioning and consistency you can only pick two. Now, with synchronous commit mode we are already sacrificing consistency because of the brief time between harden and redo. However, if we wanted to keep redo on the secondary in sync with data writes on the primary one of two things would have to happen:
The transaction is hardened and then instantaneously written to the data file (impossible).
The data modification on the primary is postponed until the change is redone on the secondary.
While the second option is technically possible but it would have a detrimental impact to performance (think about the impact HADR_SYNC_COMMIT waits can have but worse). The only way for it not to impact performance would be if we let the transaction commit and release its locks then lazily applied the change to the data file afterwards. This would be bad for many reasons but imagine for instance that your transaction is a bank transaction. You initiate a transfer of your entire balance, the transaction commits and sends a confirmation back, then you go to immediately initiate another transfer which should be disallowed but under a synchronous redo scenario that sacrifices consistency for performance, the balance would not have been updated yet despite the transaction committing.
So, in summary, the reason there is no Synchronous Redo for Always On AGs because it would be detrimental to performance and/or would violate ACID Principles.
Bitwise manipulation is when we perform a logical operation against each individual bit of a binary number. The logical connectives a.k.a. the bitwise operatorsAND, OR, and XOR can be used as masks that can affect the specific bits.
What is the point of Bitwise manipulation?
Human readability is certainly not the point, but speed and efficiency are. Bitwise operations are primitive actions that can be executed directly on the CPU meaning that they stake up less temporary/persistent storage and require less pre-processing overhead to compute. You can think of them like shortcuts.
AND
The AND logical operation can be used to turn off certain bits of a binary number, because:
1 AND 0 is 0
0 AND 0 is 0
Consider you have an input of 1101 1011 and a bitwise mask of 1111 1000. Examine the function table below:
Input
1
1
0
1
1
0
1
1
Mask
1
1
1
1
1
0
0
0
Result
1
1
0
1
1
0
0
0
Bitwise AND Mask Results
Notice that the mask only applies to the last three digits. The third to last digit is unchanged only because it was already 0.
OR
The AND logical operation can be used to turn off certain bits of a binary number, because:
1 AND 0 is 0
0 AND 0 is 0
Consider you have an input of 1001 1011 and a bitwise mask of 1110 0000. Examine the function table below:
Input
1
0
0
1
1
0
1
1
Mask
1
1
1
0
0
0
0
0
Result
1
1
1
1
1
0
1
1
Bitwise OR Mask Results
Notice that only the first three digits changed (except the first digit which was already a 1). The OR switch changed all the 0 bits to 1’s.
XOR
The XOR (Exlusive OR) logical function can be used to reverse certain bits of a binary number, because:
0 XOR 1 is 1
1 XOR 1 is 0
Consider you have an input of 1011 1001 and a bitwise mask of 0000 1111. Examine the function table below:
Input
1
0
1
1
1
0
0
1
Mask
0
0
0
0
1
1
1
1
Result
1
0
1
1
0
1
1
0
Bitwise XOR Mask Results
Notice that all four of the bits aligned with the mask are now the opposite of what they once were without exceptions. The bits have essentially been “flipped”.
Logical Shift Left
Performing a logical shift one bit to the left on a binary number means:
Moving all the bits of the number one place to the left
Discarding the most significant bit
Putting a 0 into the empty place on the right
Interestingly this is equivalent to multiply our binary number by 2. Notice that performing a logical shift three bits to the left on a binary number is the same as multiplying the number by 23 = 8.
Example:
If we start with the decimal number 14, three logical shifts to the left of its binary form results in the decimal number 112:
128
64
32
16
8
4
2
1
1410
0
0
0
0
1
1
1
0
2810
0
0
0
1
1
1
0
0
5610
0
0
1
1
1
0
0
0
11210
0
1
1
1
0
0
0
0
Logical Shift Left Results
Logical Shift Right
Performing a logical shift one bit to the right on a binary number means:
Moving all the bits of the number one place to the right
Discarding the least significant bit
Putting a 0 into the empty place on the left
As you might have guessed, this is equivalent to dividing our number by 2. Notice that performing a logical shift two bits to the right on a binary number is the same as dividing the number by 22 = 4.
Example:
If we start with the decimal number 112, two logical shifts to the right of its binary form results in the decimal number 28:
Regular expressions are notations for describing patterns of text and, in effect, make up a special-purpose language for pattern matching. Although there are myriad variants, all share the idea that most characters in a pattern match literal occurrences of themselves, but some metacharacters have special meaning, such as * to indicate some kind of repetition or […] to mean any one character from the set within the brackets.
Beautiful Code by Andy Oram, Greg Wilson
More simply, Regex (short for regular expression), is a string of text that allows you to create patterns that help match, locate, and manage text.
Below is a quick reference Javascript regex cheat sheet. If you need a more in depth refresher or a place to get started I recommend these resources on regex:
Disclaimer: For educational and demonstrative purposes only. Always test your regular expressions before applying anything to a production system. Results from the above tool are not guaranteed.
How To Use:
Type a regular expression in the Regex input box. (Leading and ending slashes are added automatically)
Type a sample string to match against in the other box.
Check out the resulting matches.
Tweak your regex expression until you get the expected results to test your knowledge.
The advent of “Big Data” is relatively new and is loosely defined as data that contains greater variety, arriving in increasing volumes and with more velocity. This is also known as the Three Vs. Greater than what? Well, greater than the data that would traditional be handled by a traditional Relational Database Management System (RDBMS).
The Three V’s
Volume – Every day, global data volume is increasing exponentially. There are many cultural, scientific and technological reasons for this including the invention and proliferation of smart phones, wearable technology, IoT devices, cloud computing, machine learning and artificial intelligence.
Velocity – The rate at which data is received and processed. Velocity has less to do with the aforementioned exponential growth of data being stored and more to do with real time streaming of that data and the need to process said data in near real time. Traditional ETL pipelines that operated on daily or even hourly batch processing just aren’t enough and so new solutions that could derive meaningful insights from data sets as they were coming in were necessary.
Variety – The increasingly varied types of data that were being processed. Constraining usable data to a predefined schema (structured data) had and still does have its advantages and in a perfect world all data would automagically be this way. But in the real world, big data solutions offer flexibility to process data much more quickly and in new ways that never would have been possible with traditional RDMS structures. These unstructured and semi-structured data types, such as text, audio, and video, require additional preprocessing to derive meaning and support metadata.
Data Structures
In the context of processing, storage and analysis, all data that exists can be categorized as either structured, unstructured or semi-structured.
Structured Data
Sometimes referred to as quantitative data. This is how all data in the enterprise used to be stored at scale. Structured data is data whose elements are addressable for effective analysis. It has been organized into a formatted repository that is typically a database. They have relational keys and can easily be mapped into pre-designed fields.
Unstructured Data
Unstructured data is a data which is not organized in a predefined manner or does not have a predefined data model, thus it is not a good fit for a mainstream relational database. It’s sometimes referred to qualitative data — you can derive meaning from it, but it can also be incredibly ambiguous and difficult to parse.
Semi-Structured Data
Data that does not reside in a relational database but that has some organizational properties that make it easier to analyze. This data probably is not as strictly typed as structured data but does enforce some rules such as hierarchy and nesting.
The job of a Building Architect is typically to design buildings, structures and civil infrastructure. Not too dissimilarly, the job of a Software Architect is to design the systems, services and infrastructure of computing systems. More importantly, just like as building architectural planning is typically the first step in any major construction project, so too is software architecture (albeit, one of the two is better suited to an agile methodology).
What is an Architectural Pattern?
An architectural pattern is a general, reusable solution to a commonly occurring problem in software architecture within a given context. The architectural patterns address various issues in software engineering, such as computer hardware performance limitations, high availability and minimization of a business risk.
You can think of an Architectural Pattern as a sort of “template” that you can use as a first step when designing the architecture of your system or application; it is not, in and of itself, an architecture. Rather, an architectural pattern is generally considered “strictly described and commonly available”. They’re designed to be broad and represent high level solutions to general software engineering problems that are reoccurring.
Just like there are many different “styles” of Building Architecture (i.e. Classical, Industrial, Victorian, Tudor, Art Deco, ect.) Software Architecture has “Patterns”.
Why use an established Architectural Pattern?
It’s good to learn from your mistakes. It’s better to learn from other people’s mistakes.
Warren Buffett, CEO of Berkshire Hathaway
Like I said before, an architectural pattern is a starting point; a template. Starting with the model that most closely fits your project’s needs has advantages:
More optimized systems – by using architectural patterns, we build transferrable models that can be reused, thus making them scalable and extensible.
Early design changes – most architectural patterns are flexible and provide you the opportunity to examine your project holistically so that you can work out errors or fundamental changes that need to be made before technical debt is accrued.
Simplification – not just for your sake but for the sake of collaboration among all the stakeholders involved. The faster stakeholders can form a mutual understanding, the faster communication, negotiation, and consensus. Obfuscation never solved anything.
Common Architectural Patterns
Below are just some of today’s most commonly used patterns:
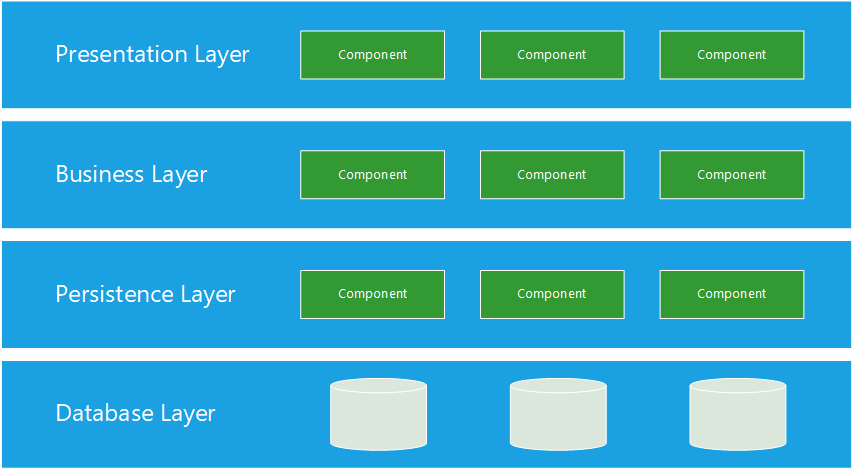
Layered
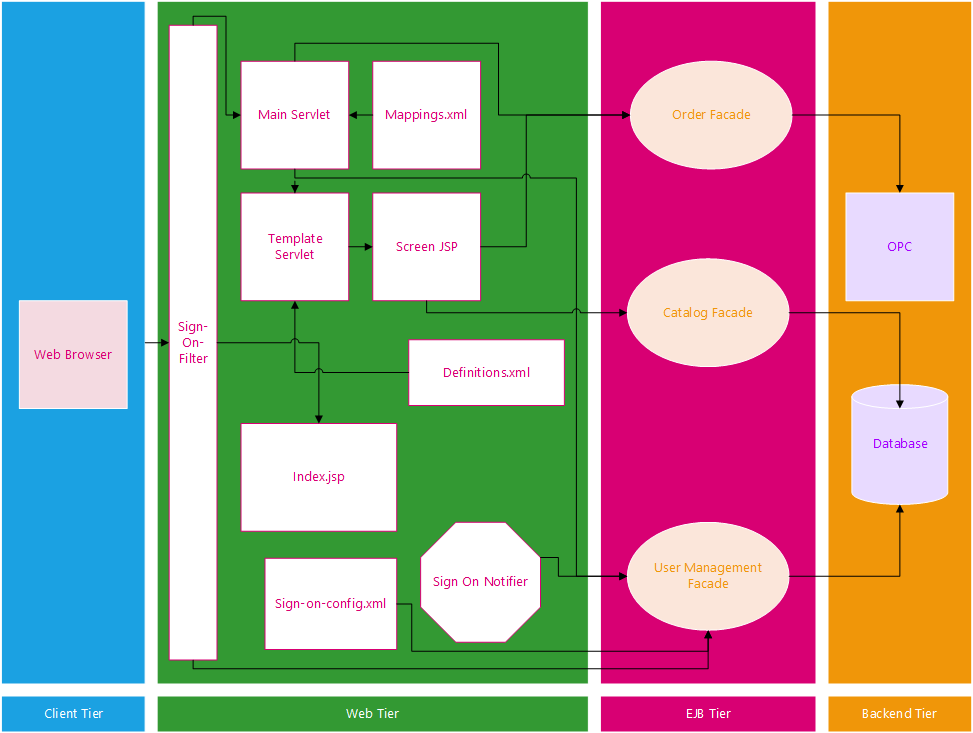
Multi-Tier
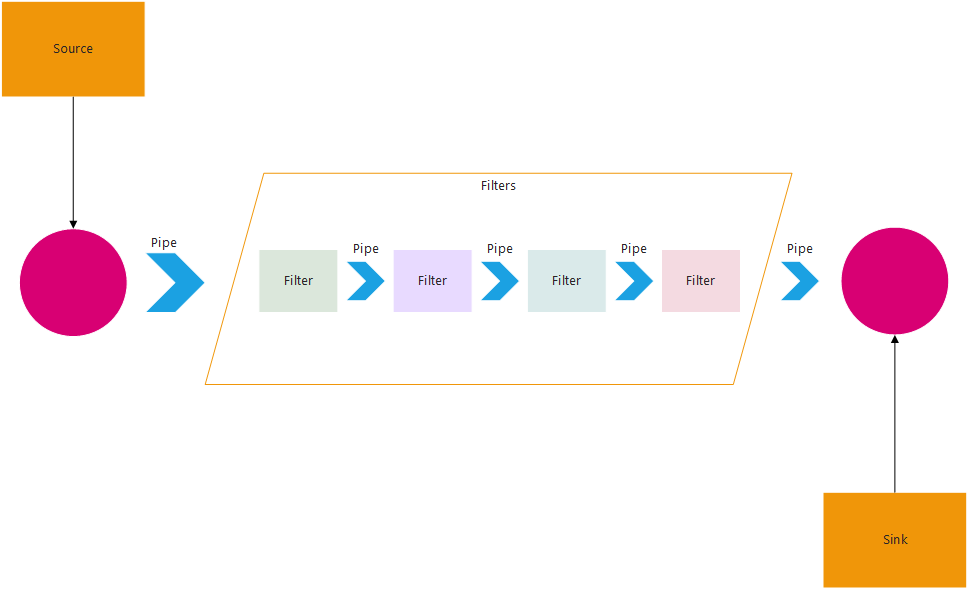
Pipe and Filter
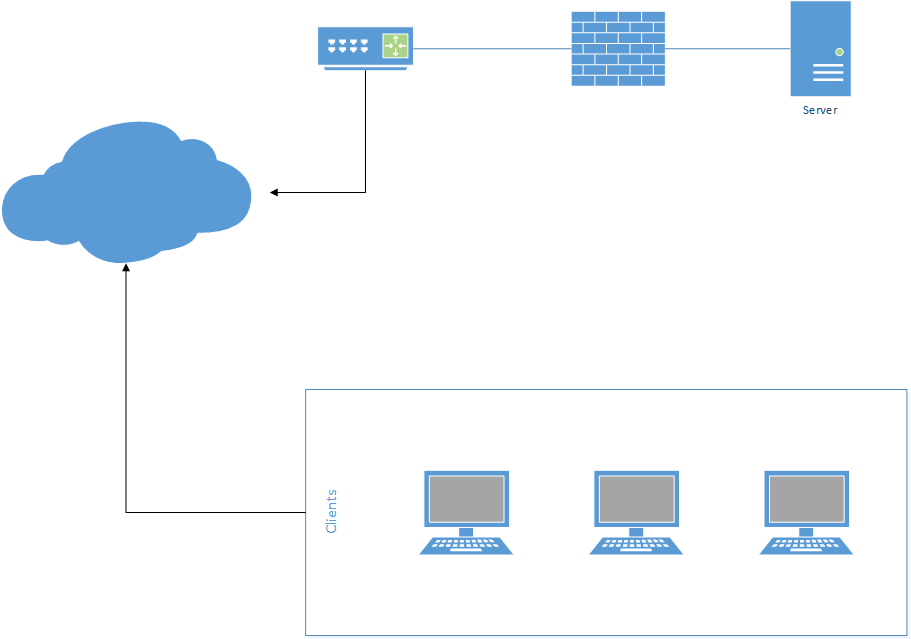
Client Server
Event-Driven
Microservices
There are many many other architectural patterns out there and this only represents a small subset of those. I may cover some of these plus others in more detail in the future via a separate post.
Below are high level conceptual diagrams for each of the above.
Layered Architecture
Multi-Tiered Architecture
Pipe and Filter Architecture
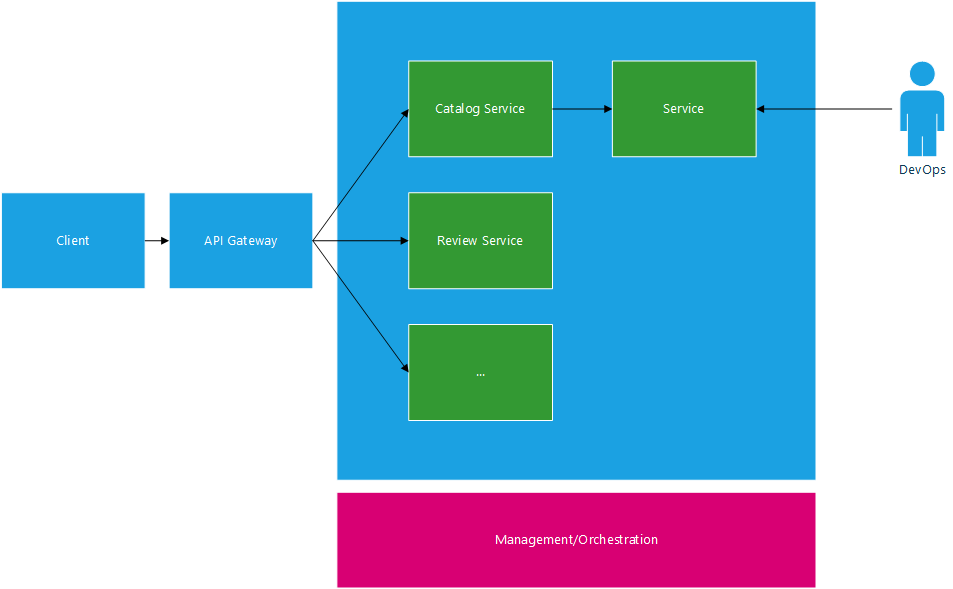
Client Server Architecture
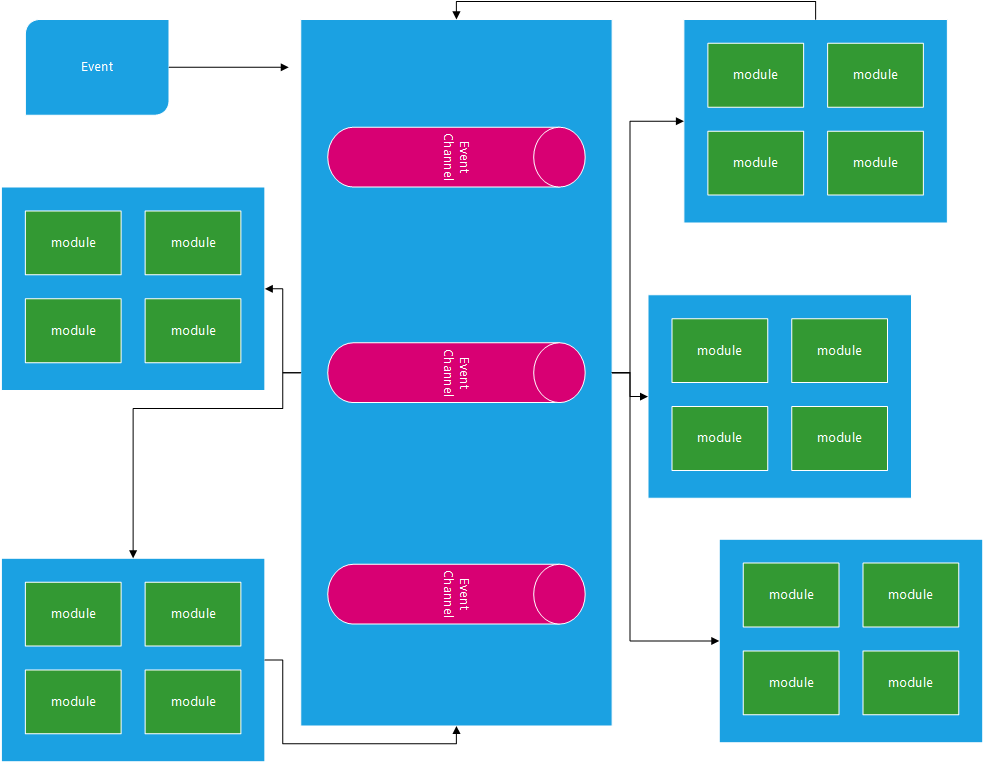
Event-Driven Architecture
Microservices Architecture
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies. You can review our cookie policy here.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.