Microsoft SQL Server Always On Availability Groups was introduced in SQL Server 2012 and were a more mature, stable and robust version of database mirroring. In fact, the AG feature was built with mirroring at its foundation. SQL Server 2014 introduced several improvements including increasing the readable secondaries count and sustaining read operations upon secondary-primary disconnections, and it provides new hybrid disaster recovery and backup solutions with Microsoft Azure.
As the feature became more mature and stable I began seeing environments that really pushed the limits of what the technology was capable of.
Always On AG Data Synchronization Flow
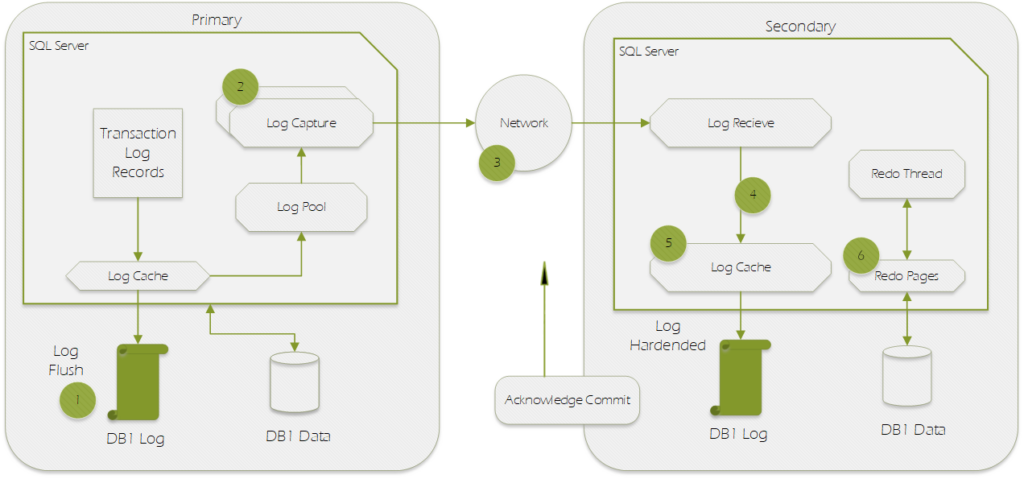
| Sequence | Step | Description |
|---|---|---|
| 1 | Log generation | Log data is flushed to disk. This log must be replicated to the secondary replicas. The log records enter the send queue. |
| 2 | Capture | Logs for each database is captured and sent to the corresponding partner queue (one per database-replica pair). This capture process runs continuously as long as the availability replica is connected and data movement is not suspended for any reason, and the database-replica pair is shown to be either Synchronizing or Synchronized. If the capture process is not able to scan and enqueue the messages fast enough, the log send queue builds up. |
| 3 | Send | The messages in each database-replica queue is dequeued and sent across the wire to the respective secondary replica. |
| 4 | Receive and cache | Each secondary replica receives and caches the message. |
| 5 | Harden | Log is flushed on the secondary replica for hardening. After the log flush, an acknowledgment is sent back to the primary replica. Once the log is hardened, data loss is avoided. |
| 6 | Redo | Redo the flushed pages on the secondary replica. Pages are kept in the redo queue as they wait to be redone. |
The diagram above demonstrates the data movement steps for a simple two node Always On AG with Synchronous Commit Enabled.
Put briefly, a transaction occurs on the Primary and waits (logged as HADR_SYNC_COMMIT waits) while the transaction is sent across the wire to the Secondary replica. The secondary replica hardens the transaction to the log then sends an acknowledgement back to the Primary. Having received confirmation from the secondary that the data is safely committed to the transaction log, the primary can now issue a commit to finish its own transaction and release any locks it may have been holding.
But wait… when exactly does redo occur? Notice that step 6 which involves the redo process is purposefully separated from the rest of the data flow. This is because even when the AG is set to Synchronous Commit, the Redo still occurs asynchronously.
Asynchronous Redo: Potential Impact From Long Failovers and Extended Recovery
Synchronous Commit is a configuration option for Availability Groups but in my opinion it is really more of a Disaster Recovery feature than a High Availability Feature because it’s primary function is to make sure that in the even of a failure of the primary node, failover to a secondary node can occur either manually or automatically with zero data loss (Disaster Recovery) but no guarantees are made about how long it takes to perform the failover (High Availability).
Because we do not commit on the primary until the transaction hardens on the primary, data consistency is guaranteed. However, since changes are applied to the data file from the redo queue on the secondary with no synchronization mechanism to prevent the primary from “getting ahead”, it is possible for the data on the secondaries to lag behind. When this occurs you will see the redo queue grow in size and failovers may take longer than expected. This is because during a failover the secondary database is brought from a Restoring/Synchronizing state to an Online state. Part of the onlining process is the three Recovery steps:
- Phase 1: Analysis
- Phase 2: Redo
- Phase 3: Undo
That’s right, as part of the failover all of the transactions that had been committed but not yet redone must now be redone before the database can come online. The same is true if there is no failover but the local instance is in the Primary role and restarts. This becomes especially burdensome if there are a high number of VLFs which likely means the not yet redone transactions are also heavily fragmented.
Asynchronous Redo: Potential Impact to Readable Secondaries
In addition to impacting failover recovery intervals, there is the potential to impact read-only data consistency. Now that sounds bad, but in my experience the scenario is quite rare. Basically, the issue manifests itself if you have an workflow that performs a DML operation on the primary and then IMMEDIATELY check for the updated row on the secondary. In this scenario it is possible that the transaction has been committed on the primary and hardened to the secondary’s log but not yet redone – leading to what appears to be inconsistent data.
So why not have synchronous redo too? Well, to understand that you need to be familiar with CAP Theorem which basically states you can’t have it all. Between high availability, partitioning and consistency you can only pick two. Now, with synchronous commit mode we are already sacrificing consistency because of the brief time between harden and redo. However, if we wanted to keep redo on the secondary in sync with data writes on the primary one of two things would have to happen:
- The transaction is hardened and then instantaneously written to the data file (impossible).
- The data modification on the primary is postponed until the change is redone on the secondary.
While the second option is technically possible but it would have a detrimental impact to performance (think about the impact HADR_SYNC_COMMIT waits can have but worse). The only way for it not to impact performance would be if we let the transaction commit and release its locks then lazily applied the change to the data file afterwards. This would be bad for many reasons but imagine for instance that your transaction is a bank transaction. You initiate a transfer of your entire balance, the transaction commits and sends a confirmation back, then you go to immediately initiate another transfer which should be disallowed but under a synchronous redo scenario that sacrifices consistency for performance, the balance would not have been updated yet despite the transaction committing.
So, in summary, the reason there is no Synchronous Redo for Always On AGs because it would be detrimental to performance and/or would violate ACID Principles.