A Queue is a FIFO (First In First Out — the element placed at first can be accessed at first) structure which can be commonly found in many programming languages. This structure is named as “queue” because it resembles a real-world queue — people waiting in a queue (line).
Just like in like real life, the person who was in line first gets served first.
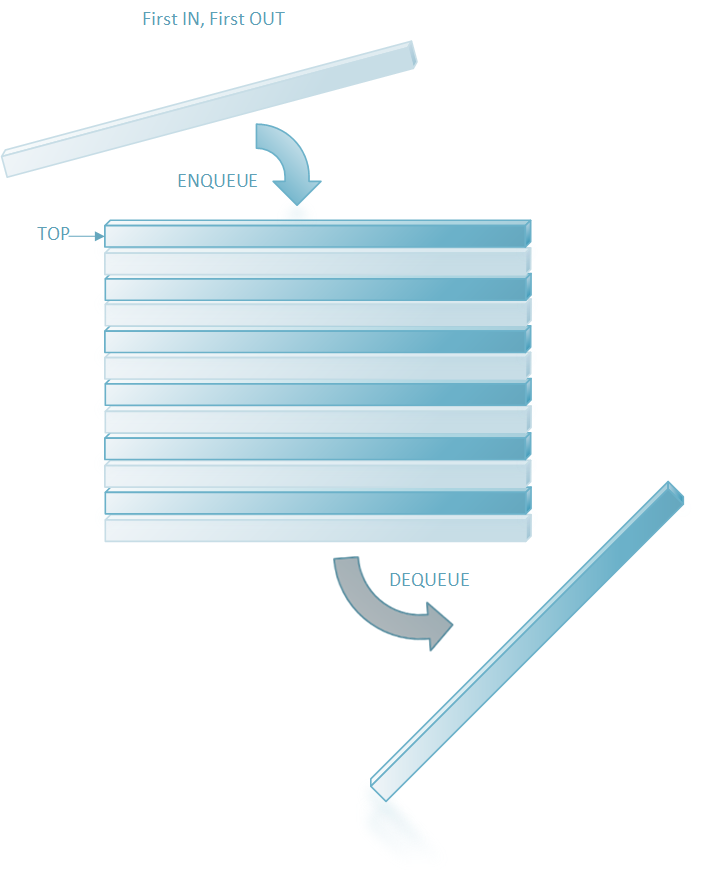
Diagram: Queue
Queue Operations
Given below are the 2 basic operations that can be performed on a queue. Reference the diagram above
Enqueue: Insert an element to the end of the queue.
Dequeue: Delete the element from the beginning of the queue.
Applications of Queues
Used to manage threads in multithreading.
Used to implement queuing systems (e.g.: priority queues).
A Stack is a linear data structure which follows a particular order in which the operations are performed. The order may be LIFO (Last In First Out) or FILO (First In Last Out).
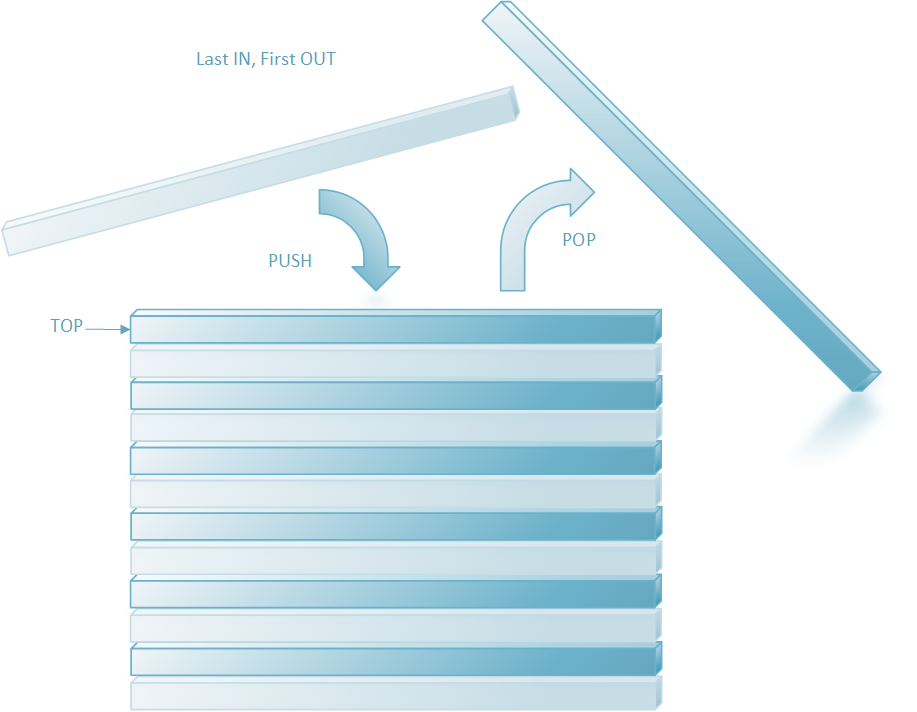
Diagram: Stack
Push: Insert an element on to the top of the stack.
Pop: Delete the topmost element and return it.
Furthermore, the following additional functions are provided for a stack in order to check its status.
Peek: Return the top element of the stack without deleting it.
isEmpty: Check if the stack is empty.
isFull: Check if the stack is full.
Applications of stacks
Used for expression evaluation (e.g.: shunting-yard algorithm for parsing and evaluating mathematical expressions).
Used to implement function calls in recursion programming.
An array is a collection of items stored at contiguous memory locations. The idea is to store multiple items of the same type together. This makes it easier to calculate the position of each element by simply adding an offset to a base value, i.e., the memory location of the first element of the array.
Diagram: Array
The diagram above demonstrates how each element can be uniquely identified by its index value or by its memory address. Notice that the memory addresses are sequential. This is what is meant by contiguous (touching). This demonstrates how and why order is preserved with arrays.
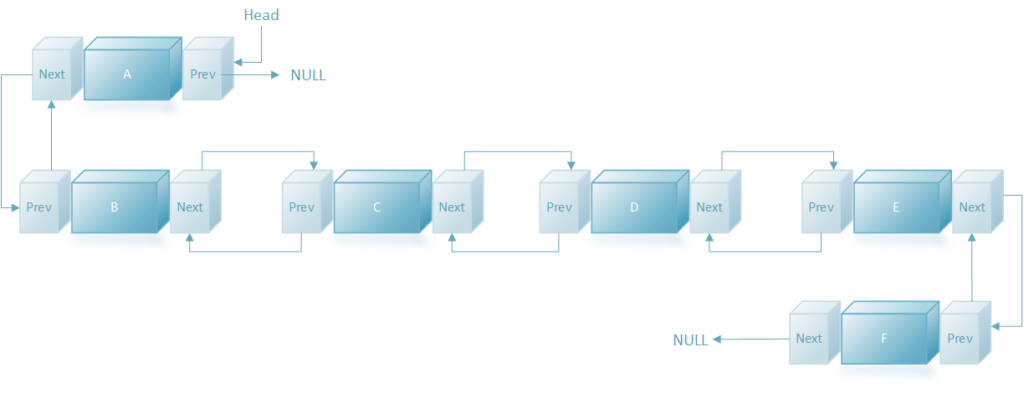
A Doubly Linked List (DLL) is very similar to a Linked List, but contains an extra pointer, typically referred to as previous pointer, together with next pointerand the data.
Diagram: Doubly Linked List
Advantages over singly linked list
A doubly linked list can be traversed in both forward and backward direction.
The delete operation for doubly linked lists is more efficient if pointer to the node to be deleted can be supplied.
Quickly insert a new node before a given node.
In a singly linked list, to delete a node, the pointer to the previous node is needed. To get the previous node, the list has to be traversed from the beginning. Whereas the doubly linked list can fetch the previous node using previous pointer.
DisadvantageS
Every node of the doubly linked list requires extra space for the previous pointer.
All operations have additional overhead because of the extra previous pointer. For example, in insertion, we need to modify previous pointers together with next pointers.
Like arrays, the Linked List is a linear data structure. Unlike arrays, linked list elements are not stored at a contiguous location; the elements are linked using pointers.
Like arrays, the Linked List is a linear data structure. Unlike arrays, linked list elements are not stored at a contiguous location; the elements are linked using pointers.
Diagram: Linked List
Why use a Linked List over an Array?
Arrays can be used to store linear data of similar types, but arrays have the following limitations: 1) Arrays have a fixed size – so we must know the upper limit (ceiling) on the number of elements in advance. Additionally, in most implementations, the memory allocation is equal to the upper limit regardless of usage. 2) Inserting new elements into an array is expensive because space has to be created for the new elements and to create space, existing elements have to be shifted. For example, in a system, if we maintain a sorted list of IDs in an array nums[]. nums[] = [100, 101, 105, 200, 206]. And if we want to insert a new ID 104, then to maintain the sorted order, we have to move all the elements after 100 (excluding 100). Deletion is also expensive with arrays. For example, to delete 101 in nums[], everything after 101 has to be shifted.
Advantages over arrays:
Dynamic size
Ease of insertion/deletion
Disadvantages:
Random access is disallowed. We must access elements sequentially starting from the first node and then traverse the list until we reach the element we are seeking. So an efficient binary search is not an option with linked lists in their default implementation.
The more segments a list is broken into the more overhead there is for locating the next linked element.
Extra memory space for a pointer is required with each element of the list.
Not cache friendly. Since array elements are contiguous locations, there is locality of reference which is not the case for linked lists.
Representation
A linked list is represented by a pointer to the first node of the linked list. The first node is called the head. If the linked list is empty, then the value of the head is NULL. Each node in a list consists of at least two parts: 1) Data 2) Pointer (Or Reference) to the next node
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies. You can review our cookie policy here.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.